- debian系或者rpm系
- 设置root用户的密码
- 最基本的命令
- 什么是shell
- PATH变量
- 管道
- 重定向
- 再学几个命令
- 文件和用户
- tar命令
- ps命令
- ssh登录
- 设置后台服务
- 网络配置
- df命令
- blkid命令
- mount命令
- 开机自动挂载
- unmount命令
- lsof命令
- telnet命令
- nmap命令
- curl命令
- 离线安装rpm包
- centos6和centos7的区别
- 通过U盘安装ubuntu
- 在ubuntu下通过ISO文件硬盘安装win7系统
- Virtualbox
- 前言
- 变量
- echo命令
- unset命令
- read命令
- bash里面的特殊符号
- if条件判断
- for循环
- 调用子命令返回值
- array
- date命令
- xargs多行转一行
- 找不到什么的错误
- 参考资料
debian系或者rpm系
目前Linux主流的包管理系统分为debian系和rpm系这两个。CentOS和Redhat属于rpm系;ubuntu和debian系统属于debian系。在ubuntu中第一个要学习的命令就是 apt 命令,通过它来进行系统软件的安装卸载更新等等工作;在centos第一个要学习的命令是 yum 命令,与apt命令类似进行了一系列的系统的软件包管理操作。
yum命令和rpm命令
- yum install what 安装某个软件
- yum groupinstall what 安装某个软件组。
- yum update 更新系统软件包
- yum remove what 卸载某个软件
- yum groupremove what 卸载某个软件组
- yum clean 清除系统软件包管理相关的缓存
- rpm -i what.rpm 本地安装某个rpm包,一般使用会加上
-vh选项来显示更多的安装信息和安装进度。 - rpm -qa| grep what 搜索本地已经安装了的名字带有what的rpm包,
apt命令和dpkg命令
系统安装好之后第一件要做的事是选一个好的源,然后安装更新。在系统设置→软件和更新那里,在“下载自”的哪里就是软件源的服务商,你最好还是自己搜索一个速度最快的源。然后在终端中执行以下命令来升级系统软件包:
- apt update 更新源
- apt upgrade 升级源下已经安装了的软件(如果有很多软件需要升级的时候推荐使用命令: (
apt dist-upgrade这样不容易出错些。) - apt install what 安装某个软件
- apt autoremove 清理软件残余
- apt autoclean 清理安装软件留下的缓存
- apt remove what 删除某个软件
- apt purge what 删除软件包括相应的软件配置
设置root用户的密码
不管Centos还是Ubuntu安装好之后,你可能已经创建了另外一个用户和它的密码,但root用户的密码还是没有设置的。进入终端然后输入: sudo passwd root 设置好密码之后,以后输入: su 就可以进入root账户了,输入: exit 退出root用户。
passwd命令当然还可以修改其他用户的密码: sudo passwd youname 。
还有一种情况是你忘了所有用户的可能密码包括root的密码,这个时候可以如下操作来修改root密码:
系统重启进入菜单选项是,按 e 进入grub的编辑模式,然后在kenerl那一行再按 e 编辑该行,行尾加上 single ,然后 Enter确认,然后按 b 进入单用户维护模式,然后用 passwd 命令来修改root密码 (此条参考了vbird的第五章 )。
最基本的命令
当我们打开终端的时候,看到一个美元 $ 符号,如果我们输入su 命令,然后进入root账户,看到开头有一个 # 符号,其中 $ 表示普通用户,# 表示现在是超级用户。然后我们看到一个波浪号 ~ ,这个波浪号的意思就是当前用户的个人家目录,比如现在我这里~ 的意思就表示目录 /home/ubuntu 。
进入Linux系统最常用的两个命令就是 ls 和 cd 。ls 命令会列出当前目录所包含的文件夹或者文件, 而 cd folder_name 就进入这个文件夹了。如果我们再输入 cd ,这个时候会回到个人的家目录那里。其实际等于执行了cd ~ 。 关于cd命令我们还需要了解cd . ,那个点表示当前目录,而 cd .. 表示返回上一级目录。然后 cd /etc ,这样我们就直接跳到系统的 /etc 目录下了。
下面这些基本的命令那是必须学会用熟的,具体使用请读者通过 --help 学习之:
- cp 复制文件命令
- which 查看系统某个命令的位置
- touch 创建某个文件或者对已存在的文件更新时间戳
- rm 删除某个文件,如果使用
-r选项也可以删除一个文件夹,也就是该文件夹和文件夹下面的所有文件。 - mkdir 创建文件夹,如果加上
-p选项可以创建多层目录。 - rmdir 删除文件夹,如果加上
-p选项可以删除多层目录,当然必须保证文件夹是空的。 - mv 移动某个文件,也可以通过这个命令来完成重命名操作。
什么是shell
shell就好像一个包装层,在shell的里面就是Linux操作系统的核心kernel,如果你要深入进去,将会遇到另外一个更加艰深的领域,比如计算机硬件啊,驱动程式啊还有Linux系统的设计核心等等之类的,这些知识都比较专业了,一般的人是不需要深究的。
Shell是提供操作系统核心(称为kernel)与用户之间交互的特殊程序,参见下图。这个kernel在启动时被装入内存,并管理系统直到关机为止。它负责建立和控制进程,管理内存、文件系统、通信等等。其他的实用程序,包括Shell在内都存储在硬盘上。kernel把程序从硬盘中装入内存,运行它们,并在程序运行结束后回收被程序占用的系统资源。Shell 是从你登录就开始运行的实用程序,它允许用户通过 Shell 脚本或者命令行的方式输入命令,并通过翻译这些命令完成用户与kernel的交互。
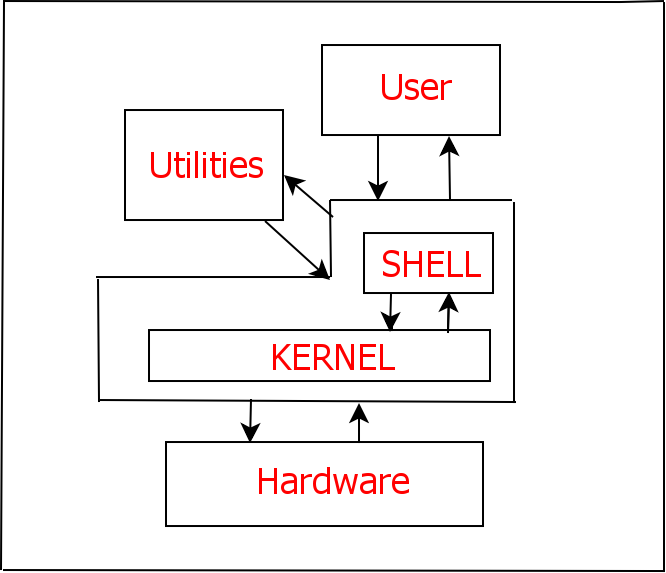
目前系统一般用的是Bourne Shell(bash shell)。本文提到shell即指bash shell,还有其他的shell这里就不讨论了
PATH变量
上面我们输入ls命令,shell是通过 PATH 这个变量来搜索相关命令的具体文件所在的。读者可以如下来查看这个变量:
echo $PATH
比如你安装了某个软件,但是通过shell却发现找不到,那么将那个软件的可执行文件目录加入到系统的 PATH 环境下就可以找到了。一般用如下语法:
PATH = $PATH:/where/your/bin
管道
简单了解了shell之后,下面简单地说明下管道和重定向这两个重要的概念,因为后面即使对于最简单的一行bash命令也可能会涉及到这两个概念。
所谓管道最简单的理解就是第一个shell命令的输出流流向了另外一个shell命令中作为输入。比如说你的火狐浏览器卡住了(随便举个例子,没别的意思。。),你需要看一下它的pid然后kill掉,那么可以如下查看:
ps aux | grep firefox
这个 | 就是所谓的管道概念,这里首先是 ps aux 命令,然后输出送入到 grep 命令中去,抓取具体包含firefox字符的匹配行。
重定向
kernel处理的每一个进程都默认都0,1,2这样三个文件说明符。其中0表示标准输入,1表示标准输出,2表示标准错误输出。所谓的标准输出一般指输出到当前的终端,而所谓的标准错误输出也是输出到当前的终端。
当文件说明符被分配给其他非终端,就叫做I/O重定向。> 是输出重定向,后面跟上输出目的地。 >> 是输出重定向的文件附加操作,也就是相当于文件操作的 a 操作。< 是输入重定向,后面跟上输入目的地。
2> 意思是标准错误输出重定向,后面跟上输出目的地。
2>&1 意思是标准错误输出重定向到标准输出。这里必须加上 & 是说重定向的目标不是一个文件而是一个文件描述符。
再来看下面这个例子:
cat *.txt > test.txt
其将本目录下glob抓取到的所有txt文件都合并成一个字符串流,然后重定向送入到test.txt文件中去。
cat *.txt 这个命令并没有什么神奇之处,神奇的是Linux终端对于文件glob操作对于 * (任意数目的任意字符)和 ? (一个任意字符)的支持。具体你可以用 echo *.txt 命令来查看一下。
再学几个命令
- clear 终端清屏,其实内容并没有清除,现在终端一般都带有记忆功能和回滚功能,如果你向上滚,还是看得到之前的内容的。
- history 显示当前登录用户已经执行过的命令,具体对应的是当前登录用户的家目录下的
.bash_history这个文件里面的内容。 - cat cat命令简单的用法就是:
cat test.txt,来查看某个文本文件的内容,但cat命令来自英文单词(concatenate),这个英文单词通用意思是联接,延伸到计算机领域现在这个单词的意思就是指将两个字符联接成一个。这里cat命令的具体功能就是将两个或者更多的字符流文件联接成为一个字符流,默认是显示到终端上,你可以通过重定向将这个字符流流向某个文件从而保存起来。 - more more命令常用来接受管道传过来的字符流信息,然后进行延缓打印方便读者阅读。
这里额外值得一提的是 windows下的 powershell也可以使用more,而且一样也可以使用管道:
type test.txt | more - head 打印文件前几行内容,可通过
-n来指定具体打印多少行。 - tail 打印文件后几行内容,同样可通过
-n来指定具体打印多少行。然后tail还有一个用法, 加上-f选项来跟踪打印文件后面附加的内容。 - uname 这个命令输入之后简单的返回"Linux"字符串,似乎用处不大。不过通过查看uname命令的帮助信息我们得知这个命令能够返回关于你目前电脑的操作系统,硬件架构,内核版本号等等重要信息。比如:
=>uname -s #内核名字
Linux
=>uname -n #主机名字
ubuntu-ubuntu
=>uname -r #内核发行号
3.13.0-36-generic
=>uname -m #硬件架构
i686
=>uname -p #处理器类型
i686
=>uname -o #操作系统名字
GNU/Linux
- whoami whoami返回当前登录用户的名字,等价于
id -un。
文件和用户
本小节另外参考了 阮一峰关于inode的文章 。
Linux系统有一句很有名的一句话,那就是 一切都是文件 。具体文件分为: 普通文件、目录文件、字符设备文件、块设备文件、链接文件、套接字文件等。
Linux操作系统要找某个文件,比如 /etc/passwd 这个文件的时候。它首先根据这个具体的文件名,也就是这一连串字符串,来找个对应的inode号,然后通过这个inode号来获取inode信息,然后根据inode信息,找到该文件所在的block,从而读出数据。
Linux具体文件名有两种写法,一种是绝对路径,一种是相对路径。所谓绝对路径就是以 / 开头的文件名,而以 . 或者 .. 开头的是相对路径写法。所谓相对路径是相对于shell当前的工作目录而言的,你可以用pwd命令来查看当shell的当前工作目录。
pwd命令
pwd命令用来查看当前工作目录在文件系统中的路径。
然后有:
/Linux文件系统开始的地方。-
~当前shell登录用户的家目录所在,对应于shell的$HOME变量的值。 -
.相对路径写法,当前目录的意思。 -
..相对路径写法,上一级目录的意思。
stat命令
stat 命令可以用来具体查看文件的一些信息。
[root@host ~]# stat /etc
File: `/etc'
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 802h/2050d Inode: 37 Links: 76
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-05 01:35:41.983000000 -0400
Modify: 2017-09-21 15:10:57.103000000 -0400
Change: 2017-09-21 15:10:57.103000000 -0400
上面这些信息除了 Inode 也就是具体的inode号(可以看作电脑认识的文件名)之外,所有这些信息都是存放在Inode table 里面的。大体有:文件大小,文件类型,权限,所有者id,所有群id,access time(上一次打开时间),modify time(上一次修改时间), change time(上一次这些inode信息比如读写权限之类的更改时间)。
下面这个是普通文件的例子,然后Links一般是1,而我们看到上面的目录文件Links不是1,其含义是有多少硬连接(hard link)指向它,一般来说是 2+n个,这里的n是该目录下面的子目录数目,而Linux下每个新建的文件夹都预先包含了 . 和 .. 这两个子文件夹,其具体用途读者应该猜到了,就是做相对路径用的(参考了 这个网页)。然后后面讨论硬连接的时候会讨论到不能硬连接文件夹,就是硬连接文件夹会破坏Linux的层级文件系统。
[root@host ~]# stat /etc/passwd
File: `/etc/passwd'
Size: 986 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 17775 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-21 11:23:26.112000000 -0400
Modify: 2017-09-21 11:23:26.112000000 -0400
Change: 2017-09-21 11:23:26.113000000 -0400
下面是块设备文件,然后其是一个文件系统,具体大小查看需要加上 -f 选项。
[root@host ~]# stat /dev/sda
File: `/dev/sda'
Size: 0 Blocks: 0 IO Block: 4096 block special file
Device: 6h/6d Inode: 9005 Links: 1 Device type: 8,0
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 6/ disk)
Access: 2017-09-05 01:36:41.869000000 -0400
Modify: 2017-09-05 01:36:41.869000000 -0400
Change: 2017-09-05 01:36:41.869000000 -0400
[root@host ~]# stat -f /dev/sda
File: "/dev/sda"
ID: 0 Namelen: 255 Type: tmpfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 61502 Free: 61465 Available: 61465
Inodes: Total: 61502 Free: 60924
ls命令
ls命令最常用的两个选项是 -a 和 -l ,一个是要显示隐藏文件(Linux系统中文件名以 . 开头的是隐藏文件),一个是显示更多更多的信息。
然后 -i 选项显示文件的Inode号。
Linux系统最精彩的部分就是管道重定向等概念将各个小的程序小的工具揉合成为一个协作的整体,下面先举个简单的例子看下:
ls *.txt
将会把一个文件夹里面的所有后缀是txt的文件名字符流扫描出来,这个字符流包含目标文件的文件名然后通过管道来进一步操作。
ls的 --sort 选项用来排序,似乎很有用,可以了解一下,但也可以通过管道传递给sort命令来进一步排序操作。如下所示:
ls *.txt | sort
ls这里抓取的文件字符流可以方便作为后面的操作,如下所示:
for i in $(ls *.txt | sort) ; do echo $i; done ;
这段代码里面的 $i 就是对应的一个个文件字符流。
-l选项详解
先看下面这个例子:
-rw-rw-r-- 1 ubuntu ubuntu 41034 8月 27 15:19 wisesystem.xoj
drwxrwxr-x 4 ubuntu ubuntu 4096 5月 28 18:50 yEd
lrwxrwxrwx 1 ubuntu ubuntu 22 9月 11 18:37 到 git 的链接 -> /home/ubuntu/桌面/git
这里最重要的是先把第一栏看懂,文件所有者和文件所有群后面再讨论。
第一栏文件属性我们可以看到开头 d 表示这个文件是目录文件,开始 - 表示这个文件是普通文件,开头 l 表示这个文件是链接文件(后面讨论的软连接和这个相关)。然后后面三个是rwx表示这个文件的所有者对这个文件可读可写可执行,如果要控制其不可执行,那么就要将其属性改为rw-,具体文件权限控制更详细的讨论在后面。
第二栏是有多少hard links连接,这个上面提到过。
第三栏是文件所有者,第四栏是文件所有群,第五栏是文件大小。第六栏是文件最近修改日期或建档日期。
UID和GID
当用户通过shell登录Linux系统的时候,其首先进入一个login接口,你需要输入用户名和密码才能进行后面的操作。
首先系统会根据 /etc/passwd 来找里面有没有你的用户名,如果有,则把UID和GID取出来,然后对应的shell和家目录也一并设置了。
然后根据UID和 /etc/shadow 文件里面的内容来核对密码。密码核对成功,那么就成功登入shell了。
/etc/passwd 内容大体如下所示:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
其具体含义是:
name:x:UID:GID:说明信息:home目录:which shell
shell有个特别的值: /sbin/nologin 表示无法登录。
继续接着上面的来,系统可以根据 /etc/passwd 获得的当前登录用户的GID来查看 /etc/group 来获得该用户的所属群组的一些信息。
root:x:0:
bin:x:1:bin,daemon
其一行的含义是:
name:x:GID:群组所含的用户,用逗号隔开
useradd和usermod命令
useradd和usermod这两个命令很多选项是类似的,简单创建一个新用户就可以
useradd new_user_name
还有很多选项设置在useradd的时候可以设置,也可以后面用 usermod 命令来设置。
其中 -d 用于设置新用户的家文件夹。然后还有个 -m 选项只能和 -d 选项一起使用如下所示:
usermod user_name -md /newhome/newpath
这是把某个用户的原家目录移到新的位置(请参看 这个网页 )。
userdel命令
userdel用于删除某个用户的数据,就是 /etc/passwd /etc/shadow 还有群组等相关数据。如果加上 -r 选项,将会把该用户的家目录也一并删除了。
groupadd和groupmod命令
类似的有groupadd和groupmod,还有groupdel命令。
su命令和sudo命令
su命令用于切换身份,最常用的一个选项是 -c ,用于以某个用户的身份执行一次命令。
su root -c "ls /root"
su命令需要新切换用户的密码,而sudo命令只需要自己的密码即可,不知道root用户的密码也没关系。Linux系统是通过 /etc/sudoers 这个文件来管理sudoer的权限的,用户不是sudoer,其是不能运行sudo命令的。
sudo -u root ls /root
上面的 -u 指定用户,默认是root用户,所以上面的 -u root 一般是不写出来的。
让某个用户是sudoer
首先运行 visudo 命令,然后跳到文件最后,找到下面这一行:
## Allows people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
将第二行 # 去掉,然后将目标用户加入到wheel群组中去:
usermod -aG wheel user_name
这样目标用户就可以执行sudo命令了。
NOTICE: 按照上面的做我不知道为什么没有成功,那么直接把你想要的用户名加上去把,大体如下:
user_name ALL=(ALL) ALL
chown和chgrp命令
前面讲到了Linux系统中所有的文件都有这两个属性:文件的所有者是谁,所有群是谁。如果当前登录用户(或者说进程执行用户)是某个文件的所有者,那么再来看这个文件权限的前三位rwx写的是什么,如果是可读则可读,如果可写那么可写。可见权限管理第一步是先管理好文件的所有者和所有群。
chown user_name filename # 改变文件所有者
chgrp group_name filename # 改变文件所有群
这两个命令都可以接受 -R 选项来递归修改该目录和目录下所谓文件的文件属性。
chmod命令
chmod命令改变文件的权限。用法是:
chmod a+x filename
chmod 755 filename
该命令可以接受 -R 选项来递归修改该目录和目录下所谓文件的文件属性。
权限有两种表示方法:
-
r ead、 w rite、执行( x )。上面的 a 表示all,除此之外还有, u ser(所有者), g roup(所有群)和 o thers(其他用户)。 + 或者 - 表示加权限或者减权限(此外还有 = 即设定某个值的意思)。
-
第二个表示方法是权限rwx分为三位,r对应数字4,w对应数字2,x对应数字1,比如说数字7那么就是rwx,比如说数字6那么就是
rw-,比如说数字5就是r-x。
目录文件权限的含义
普通文件权限的含义是很直接的,而目录文件权限的含义就不是那么直白了。
目录文件可读就是可以用ls命令列出来。
目录文件可写就是可以在该文件夹下面新建文件或子文件夹,删除里面的文件,当然包括更名等等。
目录文件可执行就是可以cd进入该目录。比如其他用户是不能cd进入 /root 文件夹里面去的。不能cd进去,里面的文件也是不能执行的,所以 web 服务器服务某个文件夹时,rx权限是要给的,w权限不能给,然后要小心,母文件夹如果权限没设置好,比如没有x权限,那么也会导致web 服务器出现权限问题:即Permission denied 错误。
硬连接和软连接
硬连接(hard link)前面已经有所谈论了,然后当时提到一个普通文件的Links一般是1,而这里讨论的创建硬连接就是创建一个新的文件名指向同一个inode节点,这就是所谓的硬连接。硬连接不能跨文件系统,不能连接目录。
软连接也叫符号连接,软连接就相当于新建一个快捷方式文件。由于硬连接有其局限,比如不能连接目录,所以实践中常用的是软连接。软连接就是创建了一个链接文件。
ln命令默认创建硬链接,加入 -s 参数是创建符号连接。
ln -s 源文件 目标文件
tar命令
打包解压文件一般使用tar命令,其同时支持gzip和bzip2这两种格式。
首先是常见的打包和解压:
tar -cf archive.tar foo bar
tar -xf archive.tar
这里 -c 的意思是创建打包文件,-f 选项指定文件名,就是后面跟着的那个 archive.tar 文件名,然后后面跟着你想打包进压缩文件的具体的文件或者文件夹名。
然后解压文件就是带上 -x 选项,你经常看到认为带上一个 -v 选项是linux命令中常见的verbose模式,就是显示更多的打印信息。
然后tar命令还支持其他格式的打包和解压,比如gzip格式,就要带上 -z 选项,文件名一般是 .tar.gz ,然后记住不管是打包还是解压都要带上这个选项。
还有bzip2格式,就要带上 -j 选项,一般文件名是 .tar.bz2 。
--exclude选项: 在压缩某个文件夹的时候排除掉文件夹里面的某个子文件夹,更确切的表述是以某个 PATTERN 来排除,所以排除某个文件也是可以得。类似的排除选项还有很多,最简单的就是直接把某个子文件夹的名字写上去,排除这个子文件夹。-C选项: 这也是很有用的一个选项,比如你想要解压出来的内容具体到某个文件夹下就用这个选项。--strip-components选项: 上面的-C选项单独使用有一个问题,那就是比如你想解压一个压缩包,其原来的文件夹目录是 what2.2/what ,那么假设你指定要解压到 /root 的test文件夹下面,其在test文件夹下面还会创建 what2.2文件夹然后再是里面的内容。而这个--strip-components和-C结合有一个很有用的用法,那就是 重命名输出文件夹 ,这个选项的用处就是将输出的文件夹路径名剔除掉几个:
比如下面这个,其原来文件夹路径名expython开头,然后定制输出到test文件夹,然后剔除所有文件文件路径名第一个,也就是expython/,这样就实现了重命名输出文件夹的功能 (参考了 这个网页 )。
tar -zxvf expython-0.2.2.tar.gz -C ./test --strip-components 1
ps命令
ps是查看系统正在运行的进程的命令,用法就是:
ps [option]
有的时候某个进程卡住了,一般运行 ps aux 来查看那个进程的进程号(PID),然后kill(kill命令,杀死某个进程。)就行了。
ssh登录
SSH协议用于计算机之间的加密远程登录。本小节主要参考了 阮一峰的ssh remote login 一文 。
ssh登录在各个操作系统都有一些便捷的工具,推荐读者先了解一下那些工具,下面主要讨论一些基本的ssh命令用法和一些基本的概念。
ssh登录命令格式如下:
ssh username@host
其中ssh默认的端口号是22,你可以通过 -p 来指定其他端口号。这里的username是远程计算机的用户名,这里的host是远程计算机的ip地址。
默认情况下ssh登录远程终端是需要输入远程计算机的密码的,你也可以通过一种将自己的公钥上传到远程计算机的方法来实现不用输入密码来登录之。首先你需要生成自己的公钥:
ssh-keygen -t rsa
具体生成的公钥文件文件在 $HOME/.ssh 那里(在windows系统下也是当前登录用户的家目录下),其为 id_rsa.pub ,还有一个 id_rsa 是什么私钥文件。然后将公钥文件上传上去即可:
ssh-copy-id username@host
如果你懒得记这个什么 ssh-copy-id 这个命令,把id_rsa.pub 也就是你的公钥文件的内容,复制粘贴到远程计算机的(你想登录的登录用户)登录用户的家目录下的 .ssh (没有新建)文件夹下的 authorized_keys 这个文件后面(没有新建)。
这样你就可以免密码ssh登录了,然后Github走ssh通道的免密码方式,也是类似的要把你的计算机的公钥文件内容设置上去。
ssh连接进行某个长时间的任务
ssh连接远程主机,然后要执行某个长时间的命令任务,如果你有一段时间没去管那个终端窗口了,ssh连接就可能会自动中断,终端之后远程的相关进程也会被kill掉。这是会返回什么 Broken pipe 错误。
一个简单的解决方案是在远程主机上执行某个命令,然后这个命令前面加上 nohup 这个命令,类似下面这种格式:
nohup thecommand
更好地解决方案是使用 screen 这个小工具,然后在远程通过screen命令来开启一个执行某个shell命令的全屏窗口(这样其就不会被自动关闭了),哪怕你本地的那个终端窗口关闭了,远程主机相关进程还是会在那里运行的。screen命令常见的用法有:
screen命令
screen -S name创建一个screen进程,并给他取个名字,后面的screen进程可以直接使用这个名字。screen -ls看看当前电脑里面都有那些screen进程。screen -r thename_or_thepid重连某个screen进程,默认只能连Detached(失连)的进程。exit完全退出Ctrl+a 再按d断连,该screen进程还在。screen -wipe清除某些Dead的screen进程。screen -D -r有的时候某个screen进程可能已经断开连接了,但其还是显示的Attached,可以用这样的选项组合来强制某个screen进程失连,然后再重连。
设置后台服务
下面将写一个后台服务脚本,让其成为Linux系统的一个后台服务。本小节参考了 这个网页 。
#!/bin/sh
### BEGIN INIT INFO
# Provides: shadowsocks
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Example initscript
# Description: The shadowsocks service
### END INIT INFO
PROG_BIN=ssserver
PIDFILE=/var/run/shadowsocks.pid
OPTIONS="--pid-file $PIDFILE -c /etc/shadowsocks/config.json"
RETVAL=0
start() {
echo -n $"Starting $0: "
$PROG_BIN $OPTIONS -d start
RETVAL=$?
return $RETVAL
}
stop() {
echo -n $"Stopping $0: "
$PROG_BIN $OPTIONS -d stop
RETVAL=$?
return $RETVAL
}
status(){
if [ -e $PIDFILE ]; then
echo $0 is running, pid=`cat $PIDFILE`
else
echo $0 is stopped
RETVAL=1
return $RETVAL
fi
RETVAL=0
return $RETVAL
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
status)
status
;;
reload|restart)
stop
start
RETVAL=$?
;;
*)
echo $"Usage: $0 {start|stop|restart|reload|status}"
RETVAL=2
esac
exit $RETVAL
然后上面的服务脚本要放入 /etc/init.d 里面去。
这个时候就可以通过 service what start+ 来调用服务脚本了。 要让服务脚本开机自启动,推荐用chkconfig+ 命令来做。
-
chkconfig --add what添加服务让chkconfig可以管理它。 -
chkconfig --del what删除服务 -
chkconfig --level <级别> what on设置服务启动级别
启动级别有:
- 等级0表示:表示关机
- 等级1表示:单用户模式
- 等级2表示:无网络连接的多用户命令行模式
- 等级3表示:有网络连接的多用户命令行模式
- 等级4表示:不可用
- 等级5表示:带图形界面的多用户模式
- 等级6表示:重新启动
似乎较常用的级别设置是 35
chkconfig --level 35 what on
网络配置
IP地址
IP地址是由32位二进制组成,表示为十进制最小 0.0.0.0 最大 255.255.255.255 。具体是由NetID和后面的HostID组成,所谓同一网域意思就是NetID相同。
IP地址的分类:
以二進位說明 Network 第一個數字的定義:
Class A : 0xxxxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==> NetI_D 的開頭是 0
|--net--|---------host------------|
Class B : 10xxxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==> NetI_D 的開頭是 10
|------net-------|------host------|
Class C : 110xxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==> NetI_D 的開頭是 110
|-----------net-----------|-host--|
Class D : 1110xxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==> NetI_D 的開頭是 1110
Class E : 1111xxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx ==> NetI_D 的開頭是 1111
五種分級在十進位的表示:
Class A : 0.xx.xx.xx ~ 127.xx.xx.xx
Class B : 128.xx.xx.xx ~ 191.xx.xx.xx
Class C : 192.xx.xx.xx ~ 223.xx.xx.xx
Class D : 224.xx.xx.xx ~ 239.xx.xx.xx
Class E : 240.xx.xx.xx ~ 255.xx.xx.xx
一般系统只有ABC三个等级。
IP只有两种IP, 一种是 公网IP ,另一个是 私网IP 。
私网IP在三个等级之下范围如下所示:
- Class A:10.0.0.0 - 10.255.255.255
- Class B:172.16.0.0 - 172.31.255.255
- Class C:192.168.0.0 - 192.168.255.255
子网掩码
子网掩码这个概念确实比较难理解,关键是不要太拘泥于某个特例细节,正如鸟哥最前面说的,子网掩码这个东西就是为了分割网域的,或者换言之一个实际存在的网域定义是由
- Network 该网域最小IP
- Netmask 子网掩码
- Broadcast 广播地址
来描述的,至于最常见的 192.168.0.0/24 这里的24是指子网掩码24个1。然后这种表达定义了完整的网域为: 192.168.0.0 - 192.168.0.255
最核心的知识就是这些,而子网掩码的重要性就在于你给定了某个具体IP,然后根据其子网掩码就可以推断出该网域的Network和Broadcast。至于子网掩码最常见的是24个1或者16个1等,但其他的都是可能的,这个是不定的。
路由
理论上只有位于同一网域内的计算机才可能直接进行文件交互,而不同网域之间的计算机的信息都是通过路由的IP分发来达到信息互通目的的。这一块刚开始会很生疏,建议跟着鸟哥的私房菜的下面这幅图好好把基本的route流程过一下:
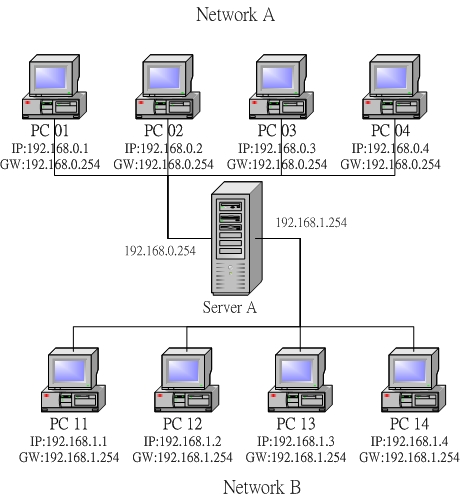
首先是每个机器上都有一个所谓的路由表,现在假设PC1要传资料给PC11,首先其会分析自己的路由表,如果发现目标IP和自己的IP在一个网域,那么就直接通过区域网功能传输数据了。
如果发现目标IP和自己的IP不再同一网域,本机会查询自己的路由表,如果没有相关设定,则封包发送给默认的路由器(gateway),然后后面类似,gateway也类似进行了一些转发工作。
route命令
route命令就是查看当前主机的路由表设置的。一般会加个 -n 参数,其会将主机名以IP的形式显示。
查看路由表需要先把第一栏 Destination 目标和 第三栏 Genmask 子网掩码组合成为网域的概念(windows下的route PRINT 是第一栏和第二栏),然后如果网关是 0.0.0.0 则是缺省值的意思,意思也就是直接通过本机的网卡interface发送。
FLAG标志 U 表示该路由可用,G 表示该路由需要网关Gateway, H 表示改行路由对应一个主机而不是一个网域。
路由表里面的规则产生有:
- 依据网络界面产生出来的IP而存在的路由
- 手工设定的路由,你所设定的路由必须是你的网卡设备或IP可以broadcast。
- 动态路由生成
route add -net 192.168.5.0 netmask 255.255.255.0 dev etho03
网卡界面设置
在 /etc/sysconfig/network-scripts/ifcfg-XXX 那里的配置是:
DEVICE=網卡的代號
BOOTPROTO=是否使用
dhcpHWADDR=是否加入網卡卡號(MAC)
IPADDR=就是IP位址
NETMASK=子網路遮罩啦
ONBOOT=要不要預設啟動此介面
GATEWAY=就是通訊閘啦
DEVICE:這個設定值後面接的裝置代號需要與檔名 (ifcfg-eth0) 那個裝置代號相同才行!否則可能會造成一些裝置名稱找不到的困擾。 BOOTPROTO:啟動該網路介面時,使用何種協定? 如果是手動給予 IP 的環境,請輸入 static 或 none ,如果是自動取得 IP 的時候, 請輸入 dhcp (不要寫錯字,因為這是最重要的關鍵字!) GATEWAY:代表的是『整個主機系統的 default gateway』, 所以,設定這個項目時,請特別留意!不要有重複設定的情況發生喔!也就是當你有 ifcfg-eth0, ifcfg-eth1.... 等多個檔案,只要在其中一個檔案設定 GATEWAY 即可
在 /etc/resolv.conf 那里设置DNS规则:
nameserver DNS的IP
在 /etc/hosts 那里设置:
私有IP 主機名稱 別名
在 /etc/sysconfig/network 那里设置:
NETWORKING=要不要有網路
NETWORKING_IPV6=支援IPv6否?
HOSTNAME=你的主機名
在 /etc/services 那里记录記錄架構在 TCP/IP 上面的總總協定,包括 http, ftp, ssh, telnet 等等服務所定義的 port number ,都是這個檔案所規劃出來的。如果你想要自訂一個新的協定與 port 的對應,就得要改這個檔案了;
在 /etc/protocols 那里定义出 IP 封包协定的相关资料,包括 ICMP/TCP/UDP 這方面的封包协议的定义等。
重启网络
/etc/init.d/network restart
這個 script 最重要!因為可以一口氣重新啟動整個網路的參數! 他會主動的去讀取所有的網路設定檔,所以可以很快的恢復系統預設的參數值。
ifconfig命令
ifconfig命令主要用来查看当前的网络配置信息,这些信息含义如下:
- eth0:就是網路卡的代號,也有 lo 這個 loopback ;
- HWaddr:就是網路卡的硬體位址,俗稱的 MAC 是也;
- inet addr:IPv4 的 IP 位址,後續的 Bcast, Mask 分別代表的是 Broadcast 與 netmask 喔!
- inet6 addr:是 IPv6 的版本的 IP ,我們沒有使用,所以略過;
- MTU:就是第二章談到的 [MTU](http://linux.vbird.org/linux_server/0110network_basic.php#tcpip_link_mtu) 啊!
- RX:那一行代表的是網路由啟動到目前為止的封包接收情況, packets 代表封包數、errors 代表封包發生錯誤的數量、 dropped 代表封包由於有問題而遭丟棄的數量等等
- TX:與 RX 相反,為網路由啟動到目前為止的傳送情況;
- collisions:代表封包碰撞的情況,如果發生太多次, 表示你的網路狀況不太好;
- txqueuelen:代表用來傳輸資料的緩衝區的儲存長度;
- RX bytes, TX bytes:總接收、傳送的位元組總量
ifup和ifdown命令
ifup {interface}
ifdown {interface}
启用或关闭某个网络界面。这两个命令实际去修改前面提到的 /etc/sysconfig/network-scripts/ 里面对应的网卡界面配置文件。
修改主机名
centos7新加入了一个命令可以很方便的修改主机名,那就是 hostnamectl ,主机名有几个类似:
- 静态主机名 static
- 瞬态主机名 transient
- 灵活主机名 pretty
hostnamectl status
hostnamectl set-hostname <hostname>
上面的第二个命令将设置所有的主机名,如果要指定具体的一个进行设置则要加上选项: --pretty, --static, 和 --transient 。
df命令
Linux系统中一切都是文件,包括硬盘光盘之类的。其中某个硬盘必须挂载到系统中的某个目录下才可以使用,比如 / 之所以可以使用是自动挂载了的。而如果你的计算机额外加上了某个硬盘,那么可能会没有自动挂载,这样是不可以使用。你需要使用挂载操作。
在执行挂载操作之前,可先用df命令来看一下当前计算机的磁盘挂载情况。
[root@host ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda2 9952216 2879484 6547532 31% /
tmpfs 258184 0 258184 0% /dev/shm
/dev/sda1 289293 141262 132671 52% /boot
Filesystem是目标文件系统,然后1K-blocks列出目标文件系统的大小,单位是KB,后面Used是已经使用了多少,Available是还有多少可用的。Use%是使用百分比,Mounted on是目标文件系统的挂载点。
blkid命令
blkid命令可以列出目标文件系统的 UUID 号,还有文件系统类型。这方便后面mount命令调用。
[root@host /]# blkid /dev/sda1
/dev/sda1: UUID="ec5c9ab8-b71e-46e6-aac9-5ccc757a02d2" TYPE="ext3"
[root@host /]# blkid
/dev/sda1: UUID="ec5c9ab8-b71e-46e6-aac9-5ccc757a02d2" TYPE="ext3"
/dev/sda2: LABEL="ROOTPART" UUID="971ffe7e-0c71-40c1-97a9-bdb6b167d4b7" TYPE="ext4"
mount命令
mount命令是具体来挂载某个文件系统的,注意挂载点,也就是对应的挂载目录最好是个空文件夹,否则原空文件里面的内容在挂载后将不可访问了。
mount -l # 列出当前计算机的挂载情况
mount -t 文件系统类型 UUID="***" 挂载点 # 具体进行挂载操作
mount -t 文件系统类型 文件系统名 挂载点
开机自动挂载
进行开机自动挂载设置就是修改 /etc/fstab 这个文件。
UUID=971ffe7e-0c71-40c1-97a9-bdb6b167d4b7 / ext4 defaults,discard,noatime 1 1
UUID=ec5c9ab8-b71e-46e6-aac9-5ccc757a02d2 /boot ext3 defaults 1 2
对照前面的例子,我们可以知道 /dev/sda1 是挂载 /boot 的。前面三项意思很清晰,那个UUID号改为目标文件系统名如 /dev/sda1 也是可以的。
下面重点讲下第四列,第五列和第六列:
-
第四列是设置目标文件系统的挂载参数的,这个mount命令通过
-o选项也可以指定。 -
async/sync 推荐设置async
- auto/noauto 是否主动测试挂载,默认auto。
- rw/ro ro就不可以写入了
- exec/noexec 是否可执行
- user/nouser nouser的意思是一般用户不可以挂载
-
defaults 同时具有rw,exec,auto,nouser,async等参数,一般设置为defaults即可。
-
和备份相关,现在第五列一般设置为0。
-
第六列,是否以fsck检查分区,现在一般设置为0即可。
unmount命令
卸载命令
unmount 目标文件系统名或者挂载点
lsof命令
我最先接触lsof命令是如下需求:查看端口号是不是被谁占用了,如果你希望释放该端口号,则kill掉该进程即可。
lsof -i :1080
lsof 命令倒不是专门为了查看端口号而设置的,其完整名字为list open files,也就是列出系统当前打开的文件的意思。由于在linux系统中, 一切皆文件 ,所以通过查看打开的文件信息能够获得很多有用的当前系统运行情况的信息。
这个命令具体使用方法很多,请读者参看 这个网页 和 这个网页 。
telnet命令
telnet命令来查看某个TCP端口是否可以正常访问。
telnet ip地址 port端口
nmap命令
扫描目标主机的端口号,参考了 这个网页。
最常见的应用需求就是查看目标主机那些端口号打开了:
nmap ip地址
curl命令
最基本的用法就是
curl the_url
你可以看作一个简单版的web browser吧,其内选项很多,从HTTP的method方法选择,到user-agent甚至cookie的设定等等都可以。
查看更多信息读者可以参考 这个网页 。
查看本机的外网ip
curl ifconfig.sh
还有 httpbin这个网站也是可以的:
curl httpbin.org/ip
离线安装rpm包
推荐安装 yum-utils 这个软件包:
yum install yum-utils
然后利用其提供的 yumdownloader 命令来下载对应的rpm包。
下载相关依赖完全实现本地安装
在安装某些rpm包的时候,可能还是需要某些依赖,要某从 fedoraproject 下载对应的epel安装包,或者干脆用yum 安装 epel-realse ,然后你还需要安装上面提及的 yum-utils ,然后运行:
yum install --downloadonly --downloaddir=. what.rpm ...
这样将自动下载并补齐这些rpm包还确实的依赖,然后你可以用上面的完全本地安装语句实现完全的面网络安装这些rpm包了。
完全本地安装
完全免网络从本地安装某些rpm包,自动解决其相互依赖问题。
yum localinstall -C --disablerepo=* what.rpm ...
centos6和centos7的区别
- 默认文件系统从ext4到xfs。
- 之前的 /bin /sbin /lib /lib64 全部移到了 /usr 下。(区别较大)
- 防火墙由iptables变成firwalld。(区别较大)
- 默认数据库由mysql变成mariadb,这个如果只是单纯的使用的话并不用考虑太多。
- python2.6升级到python2.7,这是极好的。
- 修改主机名推荐用 hostnamectl 。
- 语言字符集管理配置文件在 /etc/local.conf
- 修改时区推荐用 timedatectl 命令。
- 修改地区推荐使用 localectl 命令。
- 服务管理推荐用 systemctl 命令,不过之前的service命令也还是可以用的。然后之前的chkconfig也推荐用systemctl命令。
systemctl restart/start/stop service_name
systemctl enable/disable service_name
- 强制终止进程,之前是 \verb+kill -9 PID+ ,现在推荐使用:
systemctl kill --singal=9 PID
- ifconfig命令需要单独安装了(net-tools),现在推荐使用ip命令。
通过U盘安装ubuntu
- 在安装之前请先把硬盘中的资料做一些调整,空出一个大于20G的硬盘做将来要安装ubuntu根目录的地方。然后还需要一个大约为你内存两倍的硬盘分区等下要作为linux系统的swap交换分区。(更复杂的还可以开个分区给/home等等这里就不讨论了。)
- 到ubuntu的官网上下载系统的光盘映像。
- 用ultroiso软件(其他具有类似功能的软件也行)(注意ultroiso最好选择最新的版本,ubuntu10.10之后的一定要用9.3版本之上的)将该光盘映像写入到你的U盘中去。
- 重启计算机,BIOS稍作改动使计算机变成从U盘启动。
- 进入安装过程,其他过程都比较直观,就是硬盘分区设置上我们选择高级手动,然后将你分出来的那个20G硬盘作为/的加载点,并设置格式化成ext4日志系统(其他文件系统如ext3等也行)。然后设置交换分区,安装完成。
在ubuntu下通过ISO文件硬盘安装win7系统
-
用gparter分区
-
先mount
- 把文件复制到d盘
- 执行 sudo update-grub
- 重启到新加入的那个恢复模式下即可.
Virtualbox
网络连接模式
本小节参考了 这个网页 。
- NAT模式 网络地址转换,我的理解是Guest机发送的IP包通过主机(在这里类似做了路由器的功能)分发之后再出去的。
- 网桥模式 这个模式是最好理解的,虚拟机就类似于一台真实机器和Host同等地位的接入网络,如果你的内网不具有分发IP地址功能这种模式可能是不可行的。
- Host-only模式 可以理解Guest在Host上模拟了一张网卡,然后所有的虚拟机都是连接在这张网卡上的。所有的虚拟机可以互相访问。虚拟机和主机之间,虚拟机和外网之间都可以通过设置来实现访问。
共享文件夹设置
安装增强功能之后,在virtualbox那里设置好共享文件夹之后,记得进入客机系统,还需要如下加载文件夹:
sudo mount -t vboxsf share /home/ubuntu/share
上面的 share 名字是你在virtualbox那边设置的名字,然后具体挂载的文件夹请在客机系统那里新建一个。
前言
下面简单讲一下 bash shell 脚本知识,点到为止。就基本的了解在日常linux作业中还是很有用的。但作为一个蹩脚的编程语言【抱歉这么说】并不推荐大量编写bash脚本代码,如果有这块大量的需求,应该使用其他工具。
变量
i=2
echo $i
一般赋值就如上所示,和其他编程语言变量赋值大体类似吧,但是要特别注意变量和值之间的等号是相连的,不能用空格隔开 。变量的符号一般就是字母数字,可以加下划线。这样声明的变量为局部变量,也就是本shell中适用。如果要创建全局变量需要使用export命令。
一般使用这个变量就是在前面加上 $ 符号,如果你需要用变量的字符和其他字符组合成一个新的字符,那么需要用花括号将变量名包围起来。即这样的形式 ${i}what 。一般来说使用变量都推荐使用 ${} 这样的形式。
应用:修改终端前缀
export PS1="=>"
利用export命令就可以将这个变量变为全局变量(这里所谓的全局变量主要指子shell继承了父shell的变量。),这样所有的shell脚本都可以通用。
如果你将以上代码放入你家目录的 .bashrc 文件里面,每次终端启动都会自动加载这个文件的。这样你后面开启的那些终端前缀都会变成=> 这样的形式。
这样可以节省点屏幕空间。你可以用pwd命令查看一下,其他一切都没有影响的。
这个PS1就对应的终端的一级前缀符号,PS2对应的是进一步输入时候的提示符号。你可以换成这样的形式:
export PS2=">"
echo命令
echo命令前面接触很多了,这里不赘述了。echo命令就是用于查看某个变量的值或者直接输出一行字符串。
unset命令
取消bash某个变量的赋值。
read命令
请求用户输入某个变量的值
read name ; echo '你输入的是:'${name}
bash里面的特殊符号
上面的分号bash和其他编程语言都大体类似,就是表示一行的结束。但bash还有很多其他的特殊符号,下面讲一下,这些特殊符号有的时候看到了搜索都不太好搜索。 更多信息请参阅 这个网页 。
-
$0本命令名字,在shell脚本里面那么就成了本脚本的名字。 -
$1 $2 ...命令接受的参数 $@所有参数:{$1, $2, $3 ...},其是一个array。$?上一个命令返回的状态,一般0表示成功。$!上一个命令运行的进程号&&比如cmd1 && cmd2意思是前一个命令执行成功了再执行第二个命令&如果某个命令以&结尾,那么该命令将是异步的,进入后台执行。(PS:虽然这样,但如果你是通过远程连接服务器来创建的命令,远程关闭该后台进程也将自动关闭。这需要使用nohup或者screen。)
if条件判断
if条件语句格式是:
if [ test expression ]
then do what
fi
对于短小的shell命令行,可以写成这样的一行格式,其中分号表示换行。
if [ test expression ]; then do what ; fi
还值得提醒一下的是:条件判断语句(就是上面的test expression)要和那个方括号[]有一个空格表示分开,(上古神器都有一些怪僻,淡定就好)。
应用:确认某个文件夹是不是存在
if [ ! -d workspace ]; then mkdir workspace ; fi
-d 表示检测某个文件夹是不是存在,! 符号在这里进行逻辑否操作。也就是这里如果workspace不存在,那么新建workspace文件夹。
for循环
本小节参考了 bash for loop 这篇文章,其关于bash编程的循环部分讲的很详细。
for循环语句格式如下:
for var in 1 2 3
do cmd1
cmd2
done
同样,你也可以将其写成一行的样子:
for var in 1 2 3 ; do cmd1 ; cmd2 ; done
其中加分号的地方为多行格式下必须换行的地方。
应用:小数点递加输出流
for animate in $(seq 4.0 0.1 8.0); do echo ${animate} ; done
关于seq命令我简单说下,请通过 --help 来查阅具体信息:
用法:seq [选项]... 尾数
或:seq [选项]... 首数 尾数
或:seq [选项]... 首数 增量 尾数
应用:批量创建文件
在文件夹里面输入如下命令:
for (( i=1; i<=10; i++ )); do touch file$i.txt; done
应用:批量缩小图片大小
这是一个多行脚本,用于批量缩小图片的大小。
if [ ! -d smallsize ]; then mkdir smallsize ; fi
cd smallsize
let i=1
for it in $(ls *.png)
do convert -resize 50%x50% $it $i-$it
let i=i+1
echo $it is smallsized
done
应用:批量重命名文件
let i=1 && for f in $(ls *.jpg); do mv -vi ${f} 0000${i}.jpg && let i=i+1; done
调用子命令返回值
在前面几个例子中,已经出现多次这个形式了: $(cmd) ,其将执行子shell命令,并将返回结果作为字符串值。
array
shell编程最好不要过多涉及复杂的编程的内容,那将是很痛苦的,但是在某些情况下你可能需要了解array这个概念。下面来演示这样一个例子,其需求就是在一个自动备份程序之上再加上自动删除逻辑。
DATE=$(date +%F)
DAYS=30
## here is the autodump code, and the output filename is whatdump_${DATE}
### the allowed list
ALLOWED[0]=whatdump_${DATE}
for (( i=1; i<=${DAYS}; i++ ))
do ALLOWED[i]=whatdump_$(date -d "now -${i}days" +"%F")
done
### use the python script , it is really hard to write it on bash
python ~/thepython/scripts/whatdump_autoremove.py ${ALLOWED[@]}
这个程序整个逻辑就是创建一个名字叫做 whatdump_DATE 的备份文件(你可以通过crontab来控制好每天运行一次),然后我们希望目标文件只保留最近三十天的文件。因为这个逻辑较为复杂,本来我是打算直接将 DATE 参数传递给python脚本来做接下来的工作的,但是在了解到date命令强大的人类友好的日期时间表达功能(请参考 这个问题),我决定将整个允许存在的文件名都传递进python脚本中去。
有兴趣的可以了解下date命令-d选项的灵活表达支持,比如 date -d "now -3days" 就是现在之前三天的日期时间,而 date -d "+3weeks" 就是现在三周之后的日期时间。用兴趣的可以继续了解下,这个date命令的-d选项真的好强大。
好了下面详细讲一下这里array涉及到的语法。
赋值和引用
=>array[0]="hello"
=>array[1]="world!"
=>echo ${array[0]} ${array[1]}
hello world!
这种表达和我们常见的那种数组概念相近,记得索引从0开始这个惯例即可。或者如下一起赋值:
=>array2=("hello" "python")
=>echo ${array2[@]}
hello python
上面的 ${arrayname[@]} 这种表达方式就是引用所有的array,然后还有 ${#arrayname[@]} 这种表达是返回这个array的长度。
=>echo ${#array2[@]}
2
然后最后这句:
python ~/thepython/scripts/whatdump_autoremove.py ${ALLOWED[@]}
就是将收集到的所有允许的文件名array传递进python脚本中去了。在python脚本中一个粗糙的做法就是如下这样引用
def main(args,path=""):
print args
main(sys.argv[1:])
这样所有的这些array就传递进args里面去了,读者有兴趣可以试一下,这个args在python中就是一个列表对象了。到python里面了更复杂的逻辑我们都可以很快写出来了,我就不说了。
大概类似下面所示,注意这里的pathlib在python3.4之后才会有,之前需要用pip安装之。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import print_function
import sys
from datetime import datetime
import os
from pathlib import Path
import shutil
def main(args,path=""):
allowed = args
p = Path(path)
pfolds = [p for p in p.iterdir() if p.is_dir()]
print(pfolds)
for p in pfolds:
if p.name in allowed:
print(p.name,"passed")
else:
print(p.name,"removed")
### really do the remove thing
shutil.rmtree(p.name)
if __name__ == '__main__':
### 切换到autodump目录
os.chdir(os.path.expanduser("~/autodump"))
main(sys.argv[1:])
date命令
之所以把date命令放在一章是因为date命令如果单独作为一个命令来使用,打印显示日期其实意义不是很大。但是在bash脚本中,在管道中,date命令却变得非常有用了。读者可以用 --help 查看一下帮助信息,这个命令比我们预想的还要复杂的多,而且这里的那些输出格式参数控制语法,就是到了其他编程语言中也是有用的(比如python的time模块中的strftime函数)。
date返回日期字符
date命令返回某个特定格式的日期在某些shell脚本中很有用,如下所示就是一个简单的例子:
date=$(date +"%F_%R");echo $date
date命令前面已谈到一点,更多信息请参看 这篇文章 。这里就不赘述了。
xargs多行转一行
sudo rmdir --ignore-fail-on-non-empty $(ls -U | head -n 10000 | xargs)
这是一个批量删除空文件夹的命令,假设现在空文件夹数目很多。首先 ls -U 单纯列出来,然后管道导向 head 只打印最开始的几行,然后管道导向 xargs 命令,这样多行转成一行,就可以作为 rmdir 的参数了。
找不到什么的错误
本章节加上了一些内容,都是我遇到了说什么,No Such file等等之类的报错,一般是某些软件包依赖出了问题。下面的讨论有时是Ubuntu系统(debian系),有时是Centos(RPM系),具体看到那个包的名字,我想读者就能获得一些灵感的。
ffi.h
参考了 这个网页 。
报错: fatal error: ffi.h: No such file or directory
解决方案:
sudo apt-get install libffi-dev
opensslv.h
报错:
fatal error: openssl/opensslv.h: 没有那个文件或目录
解决方案:
sudo apt install libssl-dev
参考资料
-
网络,有关别人博客知识的引用我是能在文章中列出来就列出来,只是Linux系统的很多知识很多网页内容都很接近,已经实在不知道原创者是谁了,所以这里一并用网络这个词来表示了。在此谢谢各位博客和其他的网页编写者们了,你们的劳动传播了知识,提升了IT从业者的技能和帮助他们解决了很多问题,从而促进了整个人类的IT技术进步。也许你们没有因此赚到一分钱,和获得半点的名利,但你们做出的贡献是不能为人们遗忘的,都是得到上帝嘉许的。
-
有名的鸟哥的linux私房菜基础篇和网络篇。请参看 鸟哥的文章官网 。其中基础篇在
/linux_basic,然后网络篇在/linux_server。 -
unix编程艺术 unix编程艺术 [美] Eric S·Raymond , 姜宏 (译者), 何源 (译者), 蔡晓骏 (译者)
Comments !