前言
django是一种构建大型商务网站的解决方案,除非目前贵公司的技术栈是已经架构在django之上的,否则不管是个人性质的小项目,或者刚刚开始的新的项目,个人推荐flask多于django的。
比如作为个人爱好去搭建的小网站或者api服务,那么选择flask是很适合的。本文也是作者有时鼓捣个人的小网站慢慢积累的一些东西。
flask基础
最简单的例子
编写如下脚本,运行之,就是一个最简单的flask后台api服务了。
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'hello world'
if __name__ == "__main__":
app.run('localhost', '8080')
其他启动方式
目前flask官方文档推荐的启动方式是不直接运行上面的hello.py脚本,而是通过运行:
flask run
或者
python -m flask run
来启动flask。【这个方式很适合开发和测试,实际部署还是WSGI server来进行】
要正常执行上面的命令,你需要设置好一些环境变量,最主要的是 FLASK_APP 这个变量:
windows
set FLASK_APP=hello.py
flask run
linux
export FLASK_APP=hello.py
flask run
推荐是通过在当前工作目录下加上 .env 这个文件,里面定义:
FLASK_APP=myapp.py
FLASK_ENV=development
FLASK_DEBUG=1
环境变量,在运行 flask 命令的时候会自动加载这些环境变量。【这种加载行为只是针对flask命令,load_dotenv 模块之前该做的还是要做,不受影响。】
FLASK_DEBUG
如果设置为1则开启flask调试模式:
- 重载器 所有源码文件变动自动重启服务器
- 调试器 出现异常在浏览器中显示异常信息
生产环境一定要把调试模式关闭!
pycharm启动
pycharm现在有专门的flask启动支持,不过也可以继续采用如上描述的启动方式,这样会更加接近服务器那边的部署环境。
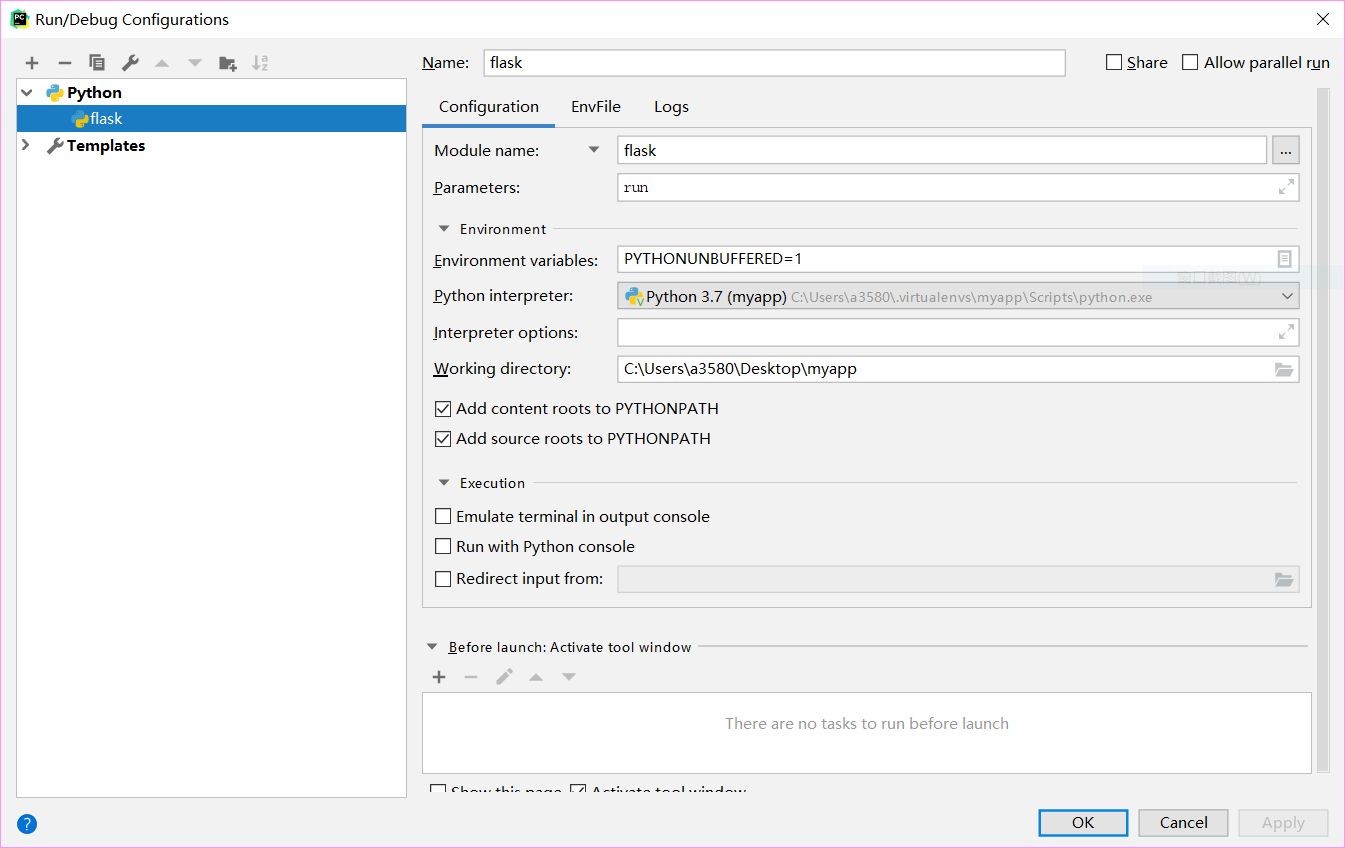
选择启动python脚本,选择 Module name ,这样就对应 python -m flask 命令的效果,然后加上参数 run ,环境变量如上所示,不用再特别调配了,工作目录设置下即可。
类似的你还可以再加上一个 python -m flask shell 命令。
url分发
url分发是web server的很核心的一个功能。flask最简单的url分发的编写就是通过app.route这样封装各个函数来实现:
@app.route('/users/<int:id>')
def get_user(id):
user = User.query.get_or_404(id)
return jsonify(user.to_json())
上面实现了一个动态路由,也就是假设用户请求 /users/1 ,到对应的函数那边将传递一个id参数进去,这个id参数类型是int型,数值是1。再来看个例子:
@app.route('/users/<username>')
def show_user_profile(username):
return username
假设现在用户请求的是 /users/zhangsan , 那么到对应的函数那边username将有值 zhangsan,这是一个字符串类型,默认前面不加类型说明的就是字符串类型。此外动态路由还支持的类型有:
- float
- path 和字符串类型,不过可以接受
/这样的符号。 - uuid
使用蓝图来管理你的项目
关于项目结构管理有很多规范,有些并不是那么必要,但推荐使用蓝图来管理你的flask项目这一点是非常重要的一点。实际上除非你的项目是最早期的那种hello world临时测试性质,否则建议马上转成蓝图组织结构。
首先推荐你编写一个 create_app 函数,这一块有些配置上的优化,这还不是很紧要的选项,暂时略过:
from flask import Flask
def create_app():
app = Flask(__name__)
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
from .errors import errors as errors_blueprint
app.register_blueprint(errors_blueprint)
return app
各个蓝图比如说errors.py内容如下:
from flask import jsonify
from flask import Blueprint
errors = Blueprint('errors', __name__)
@errors.app_errorhandler(404)
def bad_request(message):
response = jsonify({'error': 'bad request', 'message': str(message)})
response.status_code = 400
return response
@errors.app_errorhandler(401)
def unauthorized(message):
response = jsonify({'error': 'unauthorized', 'message': str(message)})
response.status_code = 401
return response
@errors.app_errorhandler(403)
def forbidden(message):
response = jsonify({'error': 'forbidden', 'message': str(message)})
response.status_code = 403
return response
然后main.py内容如下:
from flask import Blueprint
main = Blueprint('main', __name__)
@main.route('/')
def hello_world():
return {
'content': 'hello world'
}
蓝图在应用中注册写法如下:
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
蓝图的错误页面需要使用 app_errorhandler 要注册为全局的错误处理,如果是 errorhandler 则只负责本蓝图内的错误。
@main.app_errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
蓝图内注册的视图函数,用 url_for 来获取的是 main.index 这种形式,即蓝图名加上视图函数名。
url_for
url_for是很好用的一个查询flask app内部url链接的函数,具体如下:
url_for('index', _external=True)
- 名字: 默认的名字格式是
蓝图名.视图函数名,如果.视图函数名这种写法意思是当前蓝图的意思的。 - 送入一些参数进去
_external绝对路径 ,一般使用相对路径即可,浏览器之外的某些链接一定要使用绝对路径
JSON api
现在一个后台api都推荐JSON风格,如果你的返回内容是字典值,实际上现在也一般推荐返回内容是字典值,那么flask会自动用 jsonify 这个函数来处理你的返回内容,jsonify这个函数返回的flask 的response对象,然后加上了 application/json mime type头字段信息,然后当然还封装了json的dumps方法。
如果不是字典值,则需要你自己使用jsonify函数来处理返回内容。
其他技巧
flask shell命令定制
@app.shell_context_processor
def make_shell_context():
return dict(db=db, User=User, Role=Role)
运行:
flask shell
db那些变量是可以正常使用的。
cmd里面要配置好环境变量 export FLASK_APP=hello.py
加入错误页面
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'),404
如果是蓝图的话,要有全局的效果,则应该使用 app_errorhandler :
@main.app_errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
查看当前url分发情况
可以通过 app.url_map 来查看flask当前app的url分发情况。
flash消息
flash消息方便让用户知道一些必要的信息。flash函数可以实现这点。然后模板文件上需要加上:
{% for message in get_flashed_messages() %}
<div class="alert alert-warning">
<button type="button" class="close" data-dismiss="alert">×</button>
{{ message }}
</div>
{% endfor %}
静态文件
flask默认有路由:
/static/<filename>
所以你可以如下
url_for('static', filename='favicon.ico')
来直接引用static文件夹的静态文件。
flask进阶参考
在深入了解flask框架内部工作原理之后,读者可以参看我写的 flask上下文释疑这篇文章 ,然后再了解下flask具体的一些API细节即可。下面也列出了一些可做核心参考。
请求对象
request请求对象有:
- form dict 存储请求的表单字段
- args dict 存储URL上传递的参数
- values form和args的合集
- cookies dict 存储请求的所有cookies
- headers dict 存储http的headers
- files dict 存储请求上传的所有文件
- get_data 返回请求主体缓冲的数据
- get_json return dict 包含解析请求主题后得到的json
- blueprint 处理请求的Flask蓝本
- endpoint 处理请求的Flask端点名称
- method HTTP请求方法
- scheme http或https
- is_secure 通过HTTPS发送的请求返回True
- host 请求主机名
- path 请求URL路径
- query_string URL查询字符串部分
- full_path URL 路径和查询字符串部分
- url 完整URL
- base_url 同url但没有查询字符串部分
- remote_addr 远程IP地址
- environ dict 请求原始WSGI环境
请求钩子
请求钩子用装饰器来实现,flask有以下四种钩子:
- before_request 请求之前执行
- before_first_request 只在第一次请求前执行
- after_request 每次请求后执行 如果程序没有抛出异常的话
- teardown_request 每次请求之后执行,即使抛出异常
请求钩子和视图函数之间变量互通一般用上下文全局变量 g ,比如 before_request 处理的时候设置 g.user 为登录用户,后面视图函数可以调用 g.user 来得知当前登录用户。
响应对象
response = make_response(content, status_code)
response.set_cookie('a',1)
响应对象有以下属性或方法:
- status_code
- headers
- set_cookies 设置cookies
- delete_cookies 删除一个cookies
- content_length 内容长度
- content_type 响应主体的媒体类型
- set_data
- get_data
特殊的响应: 重定向响应 状态码 302 Location部分写上目标URL flask提供 redirect函数快速生成这个重定向响应对象。
abort函数 其返回的是状态码404 其是抛出异常
问题一 gunicorn多进程模式是怎样和flask作用的
参考 这个问题 的解答:
import socket
import os
def main():
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.bind(("127.0.0.1", 8888))
serversocket.listen(0)
# Child Process
if os.fork() == 0:
accept_conn("child", serversocket)
accept_conn("parent", serversocket)
def accept_conn(message, s):
while True:
c, addr = s.accept()
print 'Got connection from in %s' % message
c.send('Thank you for your connecting to %s\n' % message)
c.close()
if __name__ == "__main__":
main()
gunicorn 采用的是 pre-fork work 模式,大概作业模式如上代码所示,不同点是 gunicorn 起的主进程不负责消息处理,只负责端口监听和消息分发给子进程。
多进程的情况我们大体是熟悉的,基本上都是独立运行的内部变量类之间完全不相同的程序了。flask wsgi源码中有如下代码:
def wsgi_app(self, environ, start_response):
ctx = self.request_context(environ)
error = None
try:
try:
ctx.push()
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except: # noqa: B001
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
其中environ环境中大概有本进程的 app类,然后ctx就是所谓的请求环境,简单了解下这个对后面的讨论有帮助。
问题二 flask如何应对多线程
这个就要从 flask 源码的 globals 里面的这两行代码说起:
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
后面代码使用的 请求环境栈和应用环境栈都是这里定义的,这个LocalStack 参考了 这片文章 的讨论,借鉴了python threading 模块的 local,其是一个线程本地变量,简单来说就是其是一个字典按照线程不同id的索引,不同的id各自取各自的值,互不干扰。
所以flask在多线程下,请求环境栈和应用环境栈你可以将其看做各自不同的堆栈,互不干扰。
问题三 flask如何应对多协程
原则上如果flask使用的python的threading的local,那么对于协程问题是不能很好地应对的,这个python3.7似乎新增了一个 contextvars 模块就是为了解决这个问题的。那么问题就来了,我们知道gunicorn 可以开始多个进程的worker,而且多个进程worker之下还可以开启多个线程,除了默认的线程之外,gunicorn是还可以开启gevent之类的异步线程的。gevent之类的就是在开启多协程,那么flask能够应对这种情况吗?
flask使用的是 werkzeug定义的Local类,而在源码中我们看到这个:
try:
from greenlet import getcurrent as get_ident
except ImportError:
try:
from thread import get_ident
except ImportError:
from _thread import get_ident
也就是werkzeug会试着先加载greenlet的get_ident 函数,我想这个函数应该是支持不同的greenlet协程的,而gevent底层似乎开启的就是greenlet协程。
这就说明清楚了,也就是说flask的请求环境栈和应用环境栈不仅是线程独立的,而且还有额外对于greenlet的支持。
那么这里就提出一个问题,我估计现在flask现在应该对于python内部的asyncio协程模式是不能支持的。
问题四 请求环境栈到底做了什么工作
在请求没有到来之前,请求环境栈和应用环境栈都是空的。你要使用app类除了在代码里面直接引用之没有其他办法。
当一个请求过来了之后,请求环境栈会执行push动作,收集好当前环境的很多变量之后,比如 request session ,还有其他变量,然后将这个请求环境上下文压入堆栈,然后检查应用环境堆栈,如果为空,则会自动创建;或者默认top应用不同当前的,也会自动创建压入。
因为前面讨论过在flask能够应对的多线程多协程默认下,【下面为了讨论方便,只说线程了】,在最小的线程单元中,每个请求环境栈和应用环境栈都是不同的,都会默默记录下当前的请求环境和应用环境,都是一个请求一个请求顺序处理的。于是一个请求来,push,处理完,pop。这是很简单的模式。
具体应用环境存储做了一些优化,比如当前top的和当前一致的话就直接存储None,到时候需要的话,直接调用 current_app 来取就是了。
在取的时候采用了如下代码使用了一种惰性的动态代理机制:
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
request = LocalProxy(partial(_lookup_req_object, "request"))
session = LocalProxy(partial(_lookup_req_object, "session"))
g = LocalProxy(partial(_lookup_app_object, "g"))
然后request 和session的生存期就是本请求期,这是没有问题的。不过对于g这个变量还需要讨论下。第一个这个g最小粒度在线程这是没有问题的,各个线程之间g彼此完全不相干。而在线程内部接受的不同请求,由于他们都是引用的默认的那个相同的应用上下文环境,那么这个g是可以为多个请求公用的。但正如上面讨论的,不仅不同线程之间g不通用,而且就算某个线程内部,虽然可以应付多个请求,但对于多个应用情况来说g是和应用上下文绑定的,这些请求彼此并不公用g。
flask推荐请求之间要记住某个值,推荐使用数据库或者session这个变量,session虽然是挂在请求上下文中的,但实际在请求上下文创建的时候其是直接接受session参数的:
def __init__(self, app, environ, request=None, session=None):
这个session具体怎么传递的还不是清楚,应该在werkzeug那边。
flask推荐g的一种使用方式,是比如管理数据库的连接等,虽然g可能会为空,但只要如下,确保引用的时候,检查一下即可:
from flask import g
def get_db():
if 'db' not in g:
g.db = connect_to_database()
return g.db
@app.teardown_appcontext
def teardown_db():
db = g.pop('db', None)
if db is not None:
db.close()
问题五 多应用的情况是怎么回事
参考了 这篇文章 的讨论 ,flask是支持多应用的编码风格的:
from werkzeug.wsgi import DispatcherMiddleware
from frontend_app import application as frontend
from backend_app import application as backend
application = DispatcherMiddleware(frontend, {
'/backend': backend
})
也就是单一线程接受不同的请求,这个请求是哪个app负责的,这个请求是哪个app负责的,依靠应用上下文环境栈是支持这种情况的。
最后一般教程都会提到应用上下文环境可用于单元测试:
with app.app_context():
pass
from hello import app
from flask import current_app
app_ctx = app.app_context()
app_ctx.push()
print(current_app.name)
问题六 session到底是个什么东西
前面提到flask在创建请求上下文的时候session这个参数是不知道从哪里直接传进来的,那个flask的这个session到底是个什么东西?
首先说下背景知识:我们知道服务器那么响应内容可以设置这样的响应头: Set-Cookie ,对应flask里面的:
r = Response('test')
r.set_cookie('a','1')
客服端client或者说浏览器在接收到这样的响应之后,下次对目标服务器的请求会在请求头上加上对应的Cookie。
如下图所示:
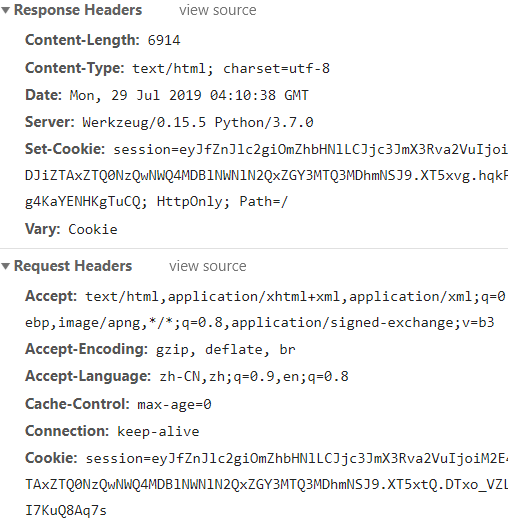
说明: 上面是第二次刷新的结果,如果用浏览器的无痕模式测试,第一次request的请求头没有Cookie的。
然后我们在上图的Cookie中看到了 session 这个字段,只是内容含义不明。这个就是对应flask里面的session:
from flask import session
只是经过了flask的加密。
第三方插件
第三方插件请读者根据需要选择使用之。
flask-migrate
flask-migrate 其基于sqlalchemy 的 alembic ,然后做了一些额外的工作。 主要提供了一些便捷的命令行接口,具体使用还是要熟悉sqlalchemy和alembic。
一个简要的例子如下:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
db = SQLAlchemy()
db.init_app(app)
migrate = Migrate(app, db)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(128))
新项目首先要运行:
flask db init
这对应alembic的 alembic init 命令,其将创建 migrations 文件夹,里面的文件就是alembic需要的,migrations文件夹是推荐和源代码一起加入版本控制的。
和简单的使用的alembic不同,其新建的 env.py 有一些优化,flask的配置环境里只要配置了 SQLALCHEMY_DATABASE_URI 这样变量,alembic就能正确找到数据库了。
然后:
flask db revision # 对应的是 alembic revison
flask db migrate # 对应的是 alembic revision --autogenerate
flask db upgrade # 对应的是 alembic upgrade
flask db downgrade # 对应的是 alembic downgrade
一般工作流程:
- 修改数据库模型或者说数据库模型发生了变动
flask db migrate创建迁移脚本- 检查自动生成的脚本,改正不正确的地方
flask db upgrade将改动应用到数据库
删除无用的迁移脚本
alembic的自动生成脚本并不是万能的,需要人工审核。而就算没问题的某些迁移脚本,如果你觉得已经毫无意义了,那么将那个版本的迁移脚本删除是没有任何问题的。
彻底从零开始的迁移脚本
虽然alembic的官方文档觉得没有这个必要,不过我觉得还是很有用的。
- 首先我们在flask应用下加上这样两个命令,负责最开始的创建数据库和根本代码生成表格工作。
- 表格生成成功之后后面都用flask-migrate 或者说 alembic来管理,经过测试比如在models.py 哪里新加一列,然后利用
flask db migrate是能够自动检测新加入了一列,从而自动生成的代码会更加精准。
from sqlalchemy_utils import database_exists, create_database, drop_database
@app.cli.command()
def initdb():
user_input = input('本命令只用于数据库初始化,后续更改请使用alembic来管理,确定请输入 [Y]')
if user_input.lower() == 'y':
engine = db.engine
if not database_exists(engine.url):
create_database(engine.url)
else:
print('db exists...')
import sys
sys.exit(-1)
assert database_exists(engine.url)
db.create_all()
from alembic.config import Config
from alembic import command
alembic_cfg = Config('migrations/alembic.ini')
command.stamp(alembic_cfg, "head")
@app.cli.command()
def dropdb():
"""
TODO 生产环境不允许调用本命令
:return:
"""
user_input = input('警告!!! 本操作将删除数据库,数据将完全丢失,确定请输入: [YYY]')
if user_input == 'YYY':
engine = db.engine
db.drop_all()
if database_exists(engine.url):
drop_database(engine.url)
else:
print('db not exists...')
assert not database_exists(engine.url)
flask-wtf
这块初接触在理解上是有点困难的,其实flask-wtf提供的主要是对WTForms这个模块的集成支持,然后还有一些功能比如 wtf.quick_form(form) 这个是 flask-bootstrap 对 WTForms的一些额外的支持。这里理解上的关键在于理解 WTForms 这个模块到底在干什么事情。
WTForms模块
简单来说WTForms模块做的工作就是方便你在模板引擎上比如jinja2模块引擎上快速创建输入表单和相关验证事宜。
首先需要定义一个Form类:
from wtforms import Form, BooleanField, StringField, validators
class RegistrationForm(Form):
username = StringField('Username', [validators.Length(min=4, max=25)])
email = StringField('Email Address', [validators.Length(min=6, max=35)])
accept_rules = BooleanField('I accept the site rules', [validators.InputRequired()])
Form类里面有一些Field类,然后Field类里面可以通过一个列表定义一系列的Validators 验证器。每个Field都有一个Widget ,Widget的任务就是负责HTML的渲染工作。
关于这个form类值得我们注意的有:
- 这个form对象,你可以通过
form.username.data来获取表单中的值。 - 如果你在定义这个form对象的时候定义了其他
validate_<field_name>函数,这些函数会针对特定的field_name而进行调用。如果验证失败,则抛出ValidationError异常,异常的信息将作为错误信息。
这个Form类在python中的代码使用如下:
@app.route('/submit', methods=('GET', 'POST'))
def submit():
form = MyForm(request.form)
if request.method == 'POST' and form.validate():
return redirect('/success')
return render_template('submit.html', form=form)
然后 flask-wtf 下的使用代码如下:
@app.route('/submit', methods=('GET', 'POST'))
def submit():
form = MyForm()
if form.validate_on_submit():
return redirect('/success')
return render_template('submit.html', form=form)
flask-wtf 定义的Form类在使用上提供的便利有:
- 会自动将
request.form或者request.files塞进去。 - 直接使用
validate_on_submit方法即可,里面集成了对 request.method 的判断——POST PUT PATCH DELETE都是可以的。
WTForms 初始化接收值,除了第一个值 request.form 等,还支持对接某个model 对象,后面还可以跟上一些关键词参数:
form = MyForm(request.form, user, username='zhangsan')
WTForms提供了很多内置的验证器支持,你还可以定义自己的验证器。这些验证器对应到上面的 validate 方法中,这个后面再说。
WTForms的渲染
上面提到的form类实例中的Field是可以直接调用str() 来获得如下的一段HTML代码的:
<input id="content" name="content" type="text" value="foobar" />
我们看到一般模板引擎渲染时,比如jinja2,会接受form实例。然后一个一般的表单渲染如下:
class LoginForm(Form):
username = StringField('Username')
password = PasswordField('Password')
form = LoginForm()
<form method="POST" action="/login">
<div>{{ form.username.label }}: {{ form.username(class="css_class") }}</div>
<div>{{ form.password.label }}: {{ form.password() }}</div>
</form>
在python代码那边,form的Field部分是可以接受一些额外的关键词参数,其将作为属性传入从而作为input标签的属性。
csrf_token相关
WTForms 已经有了 csrf_token 的支持功能:
{{ form.csrf_token }}
关于这块具体细节请参看WTForms的csrf_token相关章节,这里不深究了,一个csrf_token安全校验。
而 flask-wtf 这边推荐的写法是:
<form method="POST" action="/">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name(size=20) }}
</form>
hidden_tag 这个方法是flask-wtf提供的,就是将所有隐藏的html field 渲染在这里,因为 flask-wtf 默认会加上 csrf_token 支持,也就是上面的语句:
{{ form.csrf_token }}
这是一个hidden标签,所以最后还是会渲染在这里。
flask-bootstrap提供的额外支持
flask-bootstrap又提供了一些额外的支持,简单来说就是编写了一些jinja2的宏。比如 quick_form 宏:
{{ wtf.quick_form(form) }}
大体对应于输出这样的语句:
{% import "bootstrap/wtf.html" as wtf %}
<form class="form form-horizontal" method="post" role="form">
{{ form.hidden_tag() }}
{{ wtf.form_errors(form, hiddens="only") }}
{{ wtf.form_field(form.field1) }}
{{ wtf.form_field(form.field2) }}
</form>
这里只是说大体对应,因为quick_form 宏还有一些参数可以调配。上面对应的只是默认参数的输出情况。
然后上面的 form_errors 宏 和 form_field 宏也都是 flask-bootstrap 那个宏文件里面定义的。总之如果刚开始对表单的显示没有什么特别的要求的话, quick_form 宏还是很好用的。
有的时候有特别的要求,个人觉得是没有必要深究flask-bootstrap 那边宏定义的情况,退化为上面的写法,再稍作定制看看是否满足你的要求。否则直接用 flask-wtf 如下这种最原始的写法,再调配下即可。
<form method="POST" action="/">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name(size=20) }}
</form>
WTForms支持的Field
- BooleanField 复选框
- DateField 文本字段 for datetime.date
- DateTimeField 文本字段 for datetime.datetime
- DecimalField 文本字段 for decimal.Decimal
- FileField 文件上传字段
- HiddenField 隐藏文本字段
- FieldList 一组指定类型的字段
- FloatField 文本字段 for float
- FormField 把一个表单作为字段嵌入另一个表单
- IntegerField 文本字段 for integer
- PasswordField 密码文本字段
- RadioField 单选按钮
- SelectField 下拉列表
- SelectmultipleField 下拉多选列表
- SubmitField 表单提交按钮
- StringField 文本字段
- TextAreaField 多行文本字段
WTForms提供的Validator
- DataRequired 确保类型转换后字段有数据
- Email 验证电子邮箱
- EqualTo 比较两个字段的值 常用于比较两次密码是否输入一致
- InputRequired 确保类型转换前字段有数据
- IPAddress 验证IPv4地址
- Length 长度验证
- MacAddress 验证MAC地址
- NumberRange 数字范围校验
- Optional 允许字段没有输入,将跳过其他校验函数
- Regexp 正则表达式校验
- URL URL校验
- UUID UUID校验
- AnyOf 输入值在任一可能值中
- NoneOf 输入值不在一组可能值中
flask-login
flask-login引入进来之后 所有的jinja2模块都支持 current_user 这个变量了。
然后其提供了 login_required 来对url进行权限控制。
具体flask-login的使用请参看官方文档,这里重点讲一下flask-login都做了哪些事情,这个参考资料1说的很好。
login_user函数用于登录用户,核心任务就是将用户的id写入flask的session。类似的logout_user就是将这个id从session中删除。- 渲染jinja2模板的时候,会出现对 flask-login 的
current_user这个变量的请求。具体就是调用flask-login 的_get_user函数。_get_user首先检查session中有没有用户id,没有则返回AnonymousUser,有则调用user_loader装饰器注册的函数。【这里值得额外一提的是,在python代码那边引用current_user返回的不是数据库的User对象,要获得数据库对象需要使用current_user._get_current_object()】 login_required是对当前的current_user的is_authenticated方法进行调用,如果True 则通过,False则拒绝。
参考资料
- Flask Web 开发第二版 米格尔·格林贝格著 安道译
Comments !