ceph集群架构
本文主要基于ceph14.2.9版本。
ceph是一种分布式存储解决方案,可以融合多台计算机的存储资源于一个ceph存储集群中,并提供块设备存储、对象存储和文件系统服务。ceph提供了优良的性能,可靠性和可扩展性。可靠性就是ceph存储系统会尽可能地保证数据不会丢失,可扩展性包括系统规模和存储容量的可扩展。此外ceph在运维上还提供了自动化运维特性,包括数据自动replication;自动re-balancing;自动failure detection和自动failure recoery。
ceph最早源于Sage Weil在加州大学攻读博士期间的一篇论文——《Ceph: A Scalable Object-Based Storage System》。这篇论文基本上包含了ceph早期系统的全部知识了,其后Sage Weil又发表了下面三篇论文,来进一步说明ceph的三个核心关键点。
-
RADOS: A scalable, reliable storage service for petabyte-scale storage clusters
-
CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
-
Ceph: A Scalable, High-Performance Distributed File System.
这其中RADOS存储系统可以看作现在我们谈论的ceph存储系统的最早雏形,在最开始的时候mgr进程只是一个可选项,RADOS存储系统就是由一些mon进程和osd进程组成,不过现在ceph存储系统的一些基本功能运行也依赖于mgr进程了,所以现在我们谈及ceph存储系统就必然包含mon、osd和mgr这三个进程,后面又随着cephfs文件系统的引入和完善,相应的也引入了mds进程,因为mds进程只是就作为cephfs文件系统服务时才是必须的,所以可以把mds进程看作ceph存储系统里面的一个可选项。
然后请读者看下面这张图片:
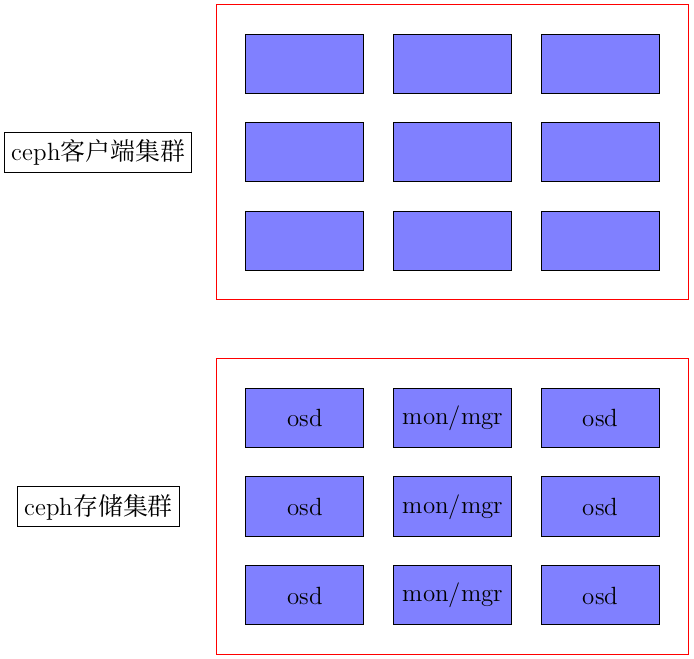
然后继续往下讲,首先一个主机里面装一个mon就可以了,然后mgr不怎么耗资源的,一般装mon进程的主机上也安装一个mgr进程。osd进程一个主机里面是可以有多个的。再就是也没有这个说法说ceph存储集群里面的主机一定要扮演某个角色,比如某个主机装osd进程了就不能安装mon进程了,也没这个说法,只是一般推荐ceph存储集群专门留一台机器只安装mon进程等而不安装osd进程,这样会让你的ceph存储集群下电osd主机时方便点,当然这个也只是个推荐。同样如果有条件的话推荐mds进程也专门弄一台主机或者mon进程和mds进程都在一台主机上,当然这也只是一个推荐,只是在服务器资源很充裕的情况下可以这样做。
下面就ceph存储集群更详细地讨论:
-
mon进程需要配置你的ceph存储集群的大多数机器,比如6个要有4台主机安装;8个要有5台主机安装等。在小规模集群上每台主机都配mon进程这问题不大,规模较大的存储集群就没必要这样做了。
-
mds进程是推荐只安装一个,然后可以适当增加几个额外的主机作为mds的standby进程。
-
osd进程具体根据你的主机的磁盘情况来配置,根据个人的实践经验,osd 的 BlueStore存储要比FileStore存储,在同样都使用机械硬盘,也就是FileStore的日志没有使用固态硬盘加速的情况下,BlueStore存储要比FileStore存储的iops快了接近两倍,所以强烈推荐BlueStore,你说固态硬盘加速,那BlueStore同样也可以对日志和db使用固态硬盘加速的。
RADOS存储系统具体到软件层面就是librados这个库,你可以基于这个librados来实现自己的存储客户端,而目前ceph官方已经实现并提供了的存储类型有:块存储、面向对象存储和cephfs文件系统存储。相应的软件层面还有librbd,librgw和libcephfs 。
我们继续往下说,读者看到上面的图将整个ceph集群分成了两个概念:ceph存储集群和ceph客户端集群。这出于以下几个理由:
- 从实践层面来说ceph存储集群是推荐另外配置高速网卡和路由来组成内网也就是所谓的cluster network的,这是处于优化ceph集群的性能的考虑。
- 从部署上来说是需要配置另外的主机来将具体对外业务和ceph存储集群分开。目前块存储和cephfs文件存储在客户端集群那里不需要安装额外的进程了,对象存储还需要额外在客户端那里启用radosgw进程,而radosgw进程是可以类似其他网络服务器一样配置多个进程多个端口的。
- 从软件层面来说,上面提及的块存储,对象存储和cephfs文件系统存储对于ceph存储集群来说最终使用者都是client这个角色类型,说的再详细一点就是所有这些不同的存储类型都是调用的librados这个库,具体就是告诉librados我要从那个pool【ceph里关于数据的逻辑分区概念】取那个ceph object。具体到ceph存储集群那边所有的ceph object的id都是唯一的,所以从理论上,假设只要只有一个osd,那么告诉这个osd我要取某某object id,那个这个osd就可以找到对应的数据了。当然实际情况因为有很多主机和osd等情况会更复杂一点,下面会谈及的。
下面我们继续往细了讲mon进程干了一些什么事,这些mon进程组成了一个mon进程群共同维护着一个cluster map,这个cluster map包含了:
- monitor map 你可以通过 ceph mon dump 来看这些信息
- osd map 你可以通过 ceph osd dump来看这些信息
- pg map 你可以通过 ceph pg dump 来看这些信息
- CRUSH map 你可以通过执行
ceph osd getcrushmap -o {filename}命令;然后用crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}反编译;然后就可以用 cat 或编辑器查看了。 - mds map 你可以通过 ceph fs dump 来看这些信息
我们可以试着看下这些信息,可以看到就是关于整个ceph集群各个成员的动态信息,因为ceph集群是动态的,而上面谈及的这些mon进程群共同维护着一个cluster map是什么意思呢?具体就是Paxos算法来实现的,其是一种基于消息传递的分布式一致性算法,有兴趣的可以研究一下,这里我就略过了。总之mons们就是利用的Paxos算法来实现了一个全局共享一致的cluster map关于本ceph集群的信息图。
此外mon进程还一个事情,那就是用户登录认证和权限管理,这一块暂时略过了。现在假设某个client要查询某个pool里的某个object_id,其首先是向附近的mon进程登录认证动作,获得回话密钥之后会想mon进程请求最新的cluster map,然后利用librados里面的CRUSH算法算一算就知道这个object_id具体在哪个osd那里了。这就是ceph最大的一个核心杀手锏所在,其强大的可扩展性就是基于CRUSH算法的算一算即可,而不需要查询某个中央数据库或者进程之类的,从而使得ceph集群极具可扩展性。
那么CRUSH算法是怎么计算的呢?简单来说如下:
- 接受client给定的pool名字和object id
- 把那个object id hash一下
- hash得到的值针对本pool的pg数量取模【这也是为什么pool的pg数量推荐是2的指数的原因,这样这里计算会快一点】从而获得pg的id
- 根据pool的名字查下cluster map得到该pool 的 id
- 然后得到如下值:
<pool_id>.<pg_id>
读者如果感兴趣的话可以运行 ceph pg dump 来看一下,你会看到类似的上面的 <pool_id>.<pg_id> 表达,然后对于某个pg来说,你会看到ACTING_SET UP_SET这个字段,这是pg里面很重要的一个概念,下面引入ceph的关于数据可靠性的处理。
ceph引入pg这个中间层概念,默认的副本数是2,意思就是该ceph集群下一个pg下面会映射2个osd,在这两个osd上针对目标数据读写默认是对行动组的第一个osd进行读写,而后面的副本osd下面简称副osd会后台自动形成目标数据的副本。
上面提到的CRUSH算法最先找到的是目标pg,然后再根据pg找到主osd,然后在主osd上找目标ceph object的数据。找到主osd之后client就会和osd直接进行对话,这也是ceph高度可扩展性的一个方面,查询读写压力直接分散在各个不同的主机上,这是一个优点,后面我会分析这也造成了ceph的某个局限性。
pg作为ceph系统提出的一个工程学上的中间层,其作用不仅仅局限在副本上,下面结合pg的状态来进一步理解之。
pg的状态
当一个pool新建之后,你指定了pg_num,然后其就开始创建pg了,这个时候pg处于creating状态。
ceph有一种心跳机制,其为了ceph的高度可扩展性也进行了优化,osd除了向mon直接报告之外,各个osd之间也会向附近的osd进行ping-pong检测,具体就是pg下的主osd检测本pg下的副osd的状态。这个过程叫做peering。理论上如果pg peering完成了一切都正常那么将进入active+clean状态。
现在假设某个pg peering之后发现本pg下的行动组健康osd数目少于ceph集群规定的副本数,那么本pg就会进入degraded状态。
还有一种情况比如说本pg主osd写了一个数据,这个时候pg会自动进入degraded状态,之后等其他副osd写动作也完成了才会进入健康状态。
在比如你新加入一个osd或者某个osd down掉了,那么你的ceph集群会重新调整pg和osd的映射分配,比如说pg A 下面有 [osd.0 osd.1] ,这个重新分配肯定要先把某个osd移除,再把某个osd加入进来,那个新加入的osd还没有同步本行动组应该有的那些数据,这个时候其他osd应该帮助那个新加入的osd同步数据,否则那个新加入的osd是不能对外正常进行服务的。这个同步的过程叫做backfilling。
上面提到的几个过程就是日常运维正常情况下都应该会看到的,属于正常状态,只要不完全陷入某个状态太长时间问题都不大。
pg还有一个数据清洗的过程,数据清洗有时会发现数据不一定的情况,其会报告该pg inconsistent , 这经常是因为你的ceph集群ntpd时间同步服务没配置好,前面提到的Paxos算法其高度依赖时间戳来判断时间的新旧,如果时间戳不同步很容易造成ceph集群对数据的新旧版本判断出现问题。
我们看到pg作为一个工程学上的中间实现层有很多状态和功能的,而且以后可能会加入更多。
下面以如何停掉一个osd进程来说明一下pg的这种状态切换,假设你要停掉某个osd进程短时间然后再重启,ceph里面有个配置默认是60s,一般来说osd 挂掉ceph集群会马上检测出来然后某些pg会切成degraded状态,但是这个时候ceph集群还不会立马就开始重新调整ceph集群里面的pg和osd映射关系并数据再分配,在这个时间段内你又启动了这个osd进程,那么pg又切成健康状态,然后整个ceph集群好像没发生什么事情一样。但是如果超过了这个时间,那么ceph就开始自动把那个对应的osd标记为out状态,一个osd标记为out状态之后ceph就开始内部再分配工作了,为了造成这样不必要的折腾,你可以设置 ceph osd set noout ,然后你的检修工作完成了,再启动那个osd进程,同样ceph集群也会跟什么事情没发生一样。
数据条带化
前面还漏掉了一个细节,那就是比如说一个文件,到client送给librados还有一个数据条带化的过程,这个数据条带化的过程受这三个配置参数的影响: 你设置的ceph object size;条带宽度;条带记数。具体我简略作图如下说明之:
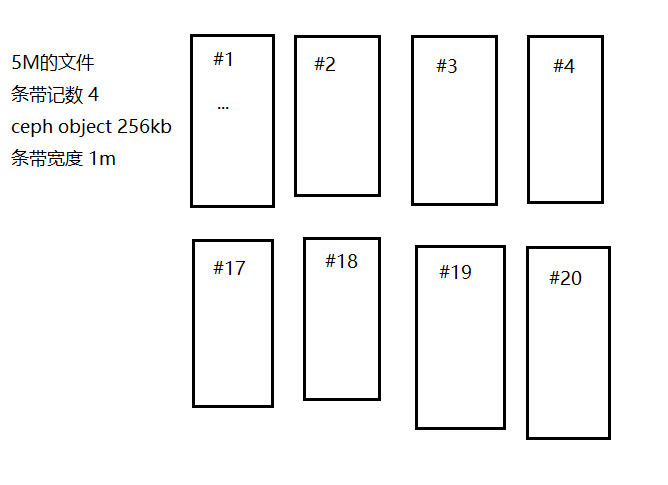
如上图所示,假设一个5m的文件,条带记数为4等,那么其会如此分割文件数据,这里可以肯定的是#1和#2会分到不同的osd。
具体这些参数你需要在ceph集群还没有数据的时候就测试并配置好,后面就不可以调配了。
用户管理和密钥
后面有时间我会补上细讲之,这里简略地讨论下cephx是一种什么安全加密手段。简单来说两个主机都拥有某个密钥,请求方用这个密钥发出请求,monitor用这个密钥进行解密得到内容,权限获得认可,则monitor发放回话ticket,然后client就可以直接用这个ticket来和目标osd或者mds进行回话了。
ceph的局限性
因为ceph的设计,造成了这样一个局限性,那就是如果某个osd读写速度过慢,那么这个过慢的osd将成为整个ceph集群性能的短桶效应所在。同时我们应该看到随着ceph集群的扩大,不可避免总会冒出那么一两个磁盘工作不正常读写过慢。现在的问题是这样将会影响整个ceph集群的性能。
我提出一个优化改进建议是,能不能pg上对行动组的各个osd针对读写性能提出某种打分策略,某些读写性能太差的将打低分,一定时间的低分主osd将自动下降为副osd,而某个副osd性能太差的话将自动被踢出行动组,并告警之。
术语解释
- rados lspools : 列出pool情况
- ceph osd tree : 列出osd的情况
- ceph metadata server 为ceph文件系统存储元数据。元数据服务器使得POSIX文件系统的用户在不对Ceph集群造成负担的前提下,执行诸如ls、find等基本命令。
- RBD rados block device 是ceph对外提供块设备服务
- MDS ceph文件系统依赖的元数据服务
- CRUSH ceph使用的数据分布算法
- 唯一标识符 Unique identifier 也就是
fsid是集群的唯一标识,你可以通过uuidgen命令来生成一个fsid,然后写入ceph的配置文件中,默认是/etc/ceph/ceph.conf。 - 集群名字 Cluster Name 每个ceph集群都有自己的名字,默认是 ceph
- 监视器名字 Monitor Name 每个集群里面的各个监视器
公网和集群内网
ceph默认你只有一个网络,也就是public network,不过推荐的设置是有两个网卡(这将会带来性能极大的提升),一个网卡: public network, 一个网卡: cluster network。cluster network最好不能连外网,这样会更加安全点。而且cluster网卡最好速度很快,这样各个osd之间通信传输数据才会高效,10Gbps是推荐。
cluster network主要是给osds通信用,所以ceph的其他组件其实还是都依赖于public network的。
cephx认证系统
ceph用cephx认证系统来认证用户和守护进程。
Cephx 用共享密钥来认证,即客户端和监视器集群各自都有客户端密钥的副本。这样的认证协议使参与双方不用展现密钥就能相互认证,就是说集群确信用户拥有密钥、而且用户相信集群有密钥的副本。
要使用 cephx ,管理员必须先设置好用户。在下面的图解里, client.admin 用户从命令行调用来生成一个用户及其密钥, Ceph 的认证子系统生成了用户名和密钥、副本存到监视器然后把此用户的密钥回传给 client.admin 用户,也就是说客户端和监视器共享着相同的密钥。