前言
本教程将从零开始讲解学习C++语言,首先先学习C语言,再继而学习C++语言。本教程各个知识点讲解由浅入深,习题充足,建议读者边阅读边编写代码实践之,这样效果更好一些。
本教程的代码在 这个github项目 中都找得到。因为visual studio的一整个项目只能有一个main函数,为了不冲突之前的例子的main函数会改写为main_test_vector之类的写法,it is not a big deal,读者知道就好。
开发环境
windows下推荐使用visual studio,虽说是C++开发环境,因为C++是C语言的超集,所以对于C语言同样也是支持的。如果你要编写C语言代码的话则选择新建空的C++项目,然后添加项的时候记得把默认的后缀 .cpp 改为 .c 。
下面将会讲解另外一种命令行风格,这对于我们理解visual studio编译输出的时候具体作了什么工作很有帮助。并不要求读者具体这样去做,如果读者有兴趣的话,可以去mingw官网下载mingw,其提供了gcc的windows移植版来方便实验。
现在假设读者已经安装mingw,并且已经设置好 PATH 系统变量了。也就是读者在cmd或者powershell里面输入gcc是有正常反应了。
如果只是一个简单的helloworld程序简单如下处理即可:
gcc helloword.c -o helloworld
但是本文后面的讨论会提到编写自己的头文件 myhead.h 和 myhead.c ,具体这块后面会讨论,而现在我们的最简单的程序如下:
#include <stdio.h>
#include "myhead.h"
int main(void) {
print_name2();
return 0;
}
然后我们要正常用gcc编译总是报错找不到 print_name2 这个函数。现在 myhead.h myhead.c 都在当前文件夹下的,也就是按照道理gcc编译器include是没出问题了,报错也说了是ld那边链接出了问题。
我们知道一个C程序从源码首先要编译为机器码,其次是将机器码文件链接成为可执行文件。简单来说就是一个C程序要经过编译和链接两个过程才能成为一个可执行文件。之前visual studio不知道做了一些什么调配,它会自动把 myhead.c 给编译进去,但是gcc是不行的。于是我们这样:
gcc helloword.c myhead.c -o helloworld
可以编译成功,但是这样太丑陋了。为什么官方内置的 stdio之类的include一个头文件就可以,它的c文件不需要编译吗?于是我们了解到一般操作系统里面的那些内置库的c源文件都已经编译成库了,有的是静态库,有的是动态库,这个在这里的讨论中不是重点。下面以静态库举例,具体过程就是:
ar rcs libmyhead.a myhead.o
ar命令后面有时间再了解,其可以简单理解为一个打包程序,你之前将一些c源码文件编译成了o机器码文件,然后ar命令将这些o机器码文件打包成为一个静态库文件。这个静态库文件的名字 libwhat.a 之前的 lib 和之后的 .a 都是固定的 ,等下你链接的时候要使用这个静态文件就要在gcc上加上选项:-l myhead 。实际上gcc本来就支持多种来源混合输入:
gcc helloword.c myhead.o -o helloworld
然后现在我们的gcc编译命令是:
gcc helloword.c -o helloworld -L . -l myhead
注意这里的选项都写在后面的,之前这个问题我纠结了好久,后来才发现这些选项写在前面gcc刷参数不会得到正确结果。anyway,继续讨论。注意这里的 -L . 这是告诉gcc新加入的库的搜索路径,这个哪怕是当前工作路径也是不会管的。
所以stdio.h之所以能够正确工作,就是因为它的那个库本来就是默认的搜索路径上的,然后-l 库加载行为已经也是默认会自动去加载的,它们应该是动态库。
我又做了一些修改,模仿mingw的文件夹结构,将自己定义的头文件放入 include 文件夹下,将生成的静态文件放入 lib 文件夹下,然后编译命令成了【-I 选项是告诉gcc额外的include搜索路径。】:
gcc hello.c -o hello -I include -L lib -l myhead
现在让我们总结一下,我们会编写很多c源码文件和h头文件,其中源码里面各个h头文件include进去的,实际上编译阶段头文件include进去具体指示把那个头文件找到,基本上做的事情就是把内容copy进来,实际的编译动作很少的,因为头文件里面就是和预处理相关的或者声明之类的。然后我们需要将预期程序中应该包含进来的c源码文件经过 gcc -c 编译成o文件,只是说这个动作有很多库之前早就做了。
然后下一步就是链接,就是将你收集整理的所有o文件用ld链接起来,前面提及的那些库也许gcc不管了,但这个时候必须链接进来了,如果不链接进来那程序里面预期的那部分内容就会缺失了。
之于C++在编译输出这块大体情况和上面的讨论相同就不赘述了。
visual code编辑器调配
visual code编辑器那里,我们希望实现一种效果,随便写一个 helloworld.c 文件,然后就可以正常编译运行。默认的那个 cpp插件 经过调配是可以执行编译动作的,具体更多细节请参看该插件的官方文档部分,但个人推荐 code runner 这个插件,说到底我们只是希望能够将上面那一行命令更快捷的生成执行罢了,默认的那个cpp插件有点麻烦了。具体到c大概做了如下修改:
"code-runner.executorMap": {
......
"c": "cd $dir && gcc $fileName -o $fileNameWithoutExt -I include -L lib -l myhead && $dir$fileNameWithoutExt"
},
然后右键就可以看到run code这个菜单项。
C语言版helloworld
下面是C语言的实现helloworld的最简单最简单的版本:
#include <stdio.h>
int main(void){
printf("hello world.\n");
}
就是定义了一个函数,这个函数名比较特殊,叫做 main ,是默认程序的入口函数名。然后利用printf函数打印了一个字符串,而这个printf函数需要你引入stdio这个包。
下面这个版本稍微做了一些修改:相比较一般的helloworld程序多了个system函数,主要是让屏幕暂停一下,否则屏幕会一闪而过,我们会看不清具体打印了什么字。【在visual studio那边不需要这个修改,gcc这边加入这个修改会让后面几个例子方便点。】
#include <stdio.h>
#include <stdlib.h>
int main(void) {
printf("hello world!\n");
system("pause");
return 0;
}
按照C11的标准推荐main函数采用这样的写法:
int main(void){
}
头文件
C语言从源码到可执行程序 在各个操作系统平台上具体细节各有不同,但总会分为编译阶段【将C语言代码转成汇编语言代码】和 链接阶段【将汇编语言代码汇总】,现在我们关注编译阶段即可。
编译阶段也就是C语言编译器处理你写的C语言源码的过程,在这个过程中,C语言编译器会进行很多工作,一般推荐将这些和C语言编译器相关的工作代码汇总写入头文件中。
我们看到的 # 开头的命令都是C语言编译器的预处理过程相关的命令,比如 #include 。
定义宏
#define 命令定义了一个宏,其实就是一个简单的C语言编译器预处理阶段的文本替换操作,比如:
#define PI 3.14
这里需要提醒一点的是,这个PI并不是后面C语言中讨论的常量或者变量,它就是一个文本替换操作,比如:
printf("The PI is %f \n", PI);
实际上源码经过预处理之后是:
printf("The PI is %f \n", 3.14);
编写自己的头文件
首先我们新建一个 myhead.h 头文件,里面的内容就是:
#include <stdio.h>
#define PI 3.14
上面两个包反正后面应该经常遇到,这里先一并包含进来了。
然后我们的主程序 test_myhead.c 就是:
#include "myhead.h"
int main(void) {
printf("The PI is %f \n", PI);
return 0;
}
读者一定注意到 #include 后面写法上有点差异,简单来说尖括号包围的主要是标准库或者系统标准目录里面能够找到的;而双引号包围的先从当前目录寻找,找不到再在标准系统目录下找,具体各个操作系统标准目录定义这里略过讨论了。
具体自己编写的头文件visual studio那边是可以直接用的,其他环境请参照上面的讨论。
更规范的头文件写法
头文件的更多编写细节后面会继续讨论,这里主要说些头文件一般会加入如下写法:
#ifndef MYHEAD_H_
#define MYHEAD_H_
#include <stdio.h>
#define PI 3.14
#endif // !MYHEAD_H_
意思是如果没有定义 MYHEAD_H_ ,则定义 MYHEAD_H_ ,并继续执行头文件的其他内容,否则跳过。这是为了防止头文件被多次使用并多次加载。
自己定义函数
helloworld程序里面包含了很多信息,至少对于刚接触C语言的读者来说是的。看完helloworld程序,读者就应该知道C语言函数的写法了:
return_type function_name(function_parameters){
// this is a comment.
/* this is also a comment.*/
return 0;
}
具体更多的细节后面再慢慢讨论,其实C语言是一个很简单的语言。
C90新增了函数原型的概念,比如:
int add1(int a) {
return a + 1;
}
的函数原型是:
int add1(int a);
函数原型也叫做函数声明,告诉编译器正在使用某个函数,函数声明语句一般放在头文件中。
头文件里面加入函数原型
继续之前的描述,我们在 myhead.h 文件里面加上:
int add1(int a);
然后我们新建一个 myhead.c 文件,加入函数定义:
int add1(int a) {
return a + 1;
}
test_add1.c 里面直接使用你定义的add函数即可。
#include <stdio.h>
#include "myhead.h"
int main(void) {
printf("5 + 1 = %d \n", add1(5));
return 0;
}
基本数据类型
| name | 说明 | printf输出 |
|---|---|---|
| int | 整型 | %d |
| float | 浮点型 | %f 【%e对应指数表示】 |
| char | 单字符型 | %c |
| long | 长整型 | %ld |
| double | 双浮点型 | %f 【%e对应指数表示】 |
| _Bool | 布尔型 | %d |
C语言的char单字符型是用单引号表示的:
char a = 'a';
C99新增了_Bool也就是布尔型,其实际上也是一种整数型,0表示false;1表示true。
自动类型转换
C语言遇到不同数据类型运算,会发生自动类型转换的情况有 char -> int int -> double ,当然也包括 char -> double 。
强制类型转换
(int)(3.14)
强制类型转换不影响原变量,是运算时的截取操作,不是四舍五入。
布尔值
推荐使用stdbool包,其让bool称为_Bool的别名,此外你还可以使用true和false。C++里面有类似的用法,除了你不需要再声明引入stdbool包了,anyway,总的原则就是不要再使用0和1来表示布尔值了。
计算最大公约数
下面作个计算最大公约数的题目来巩固下前面所学的东西。
除法和求余数
下面主要演示下除法和求余数,其他加法减法乘法还是很直白的。
float x = 12.2;
float y = 2;
// 一般除法
float z = x / y;
printf("z is: %f.\n", z);
// 求余数或者说取模
int w = 13 % 2;
printf("w is: %d.\n", w);
欧几里得算法
本小节主要参考了维基百科的 欧几里得算法,这里程序不是很复杂,关键是理解算法思想。欧几里得算法最核心的思想是:
两个数的最大公约数等于相对较小的那个数和两个数的差的最大公约数。
简要证明如下:
a = mk
b = nk
a和b的最大公约数是k,所以m和n互质
于是有:
a-b = (m-n)k
b = nk
现在的任务就是要证明m-n 和n是互质的,反证,假设 m-n 和 n 不是互质的,则有:
m-n = ix
n = iy
于是:
m = n+ ix = i(x + y)
我们得 m 与 n 是可以同时被i整除的,这和之前的m和n互质假设违背,
于是我们得到 m-n 和 n是互质的,于是进一步得到:
a-b 和 b的最大公约数也是 k。
现在假定b是一个较小的数,则以上过程可以记作:
gcd(a, b) = gcd(b, (a-b))
这个过程总是在取最小的那个数和原来两个数的差,所以一直下去会让这两个数对变得更小而趋近于原点。现在假设新的两个数对a不等于b,那么这个过程并没有终止,还可以继续下去。那么现在假设a等于b,则我们说现在已经找不到最小的那个数了,于是过程终止。
举例:
36 ~ 9 => 9 ~ 27 => 9 ~ 18 => 9 ~ 9 => 最大公约数为9
现在编写代码如下:
int gcd(int a, int b)
{
int temp;
while (a != b) {
if (a > b) {
temp = a - b;
a = b;
b = temp;
}
else if (a < b) {
temp = b - a;
b = temp;
}
}
return a;
}
程序逻辑
程序逻辑上C语言和C++语言区别非常的小,这块和其他编程语言除了写法上的差异实际上区别也很小。我们在上面的例子中就已经看到了if语句和while语句,下面再继续介绍for语句:
for (int i; i< 3; i++){
print(i);
}
其中第一个分号前面是循环体的初始化语句,第二个是循环体终止判断语句,最后那个是循环体每执行一次循环主体之后要执行的语句。
关于这块多说点,稍微接触点某种编程语言的人都会觉得啰嗦,而对于初学者我决定这块也不作过多讨论,读者后面阅读耳濡目染也会慢慢熟悉起来,实在不懂上网搜索也是问题不大的。
字符串数据类型
现在讨论字符串数据类型决定更多地是强调其内部存储形式,弱化字符串的输入输出操作和相关字符串的操作函数相关的讨论了。C++里面一般推荐使用string类,不过C的传统字符串数据类型也经常用到。即使是使用传统的字符串类型相关输入输出操作cin和cout也更好用些。所以在这里的讨论能够不提及printf和scanf的相关细节就不提及,而相关的字符串操作函数也只是提及那些最基本常用的。
字符串简单来说就是一个字符型数组,以 '\0' 结束,比如 "sam" 实际存储的值如下所示:
void print_name(void) {
char name[4];
name[0] = 's';
name[1] = 'a';
name[2] = 'm';
name[3] = '\0';
printf("name is %s\n", name);
}
C语言数组初始化是支持这样的形式写法的:
void print_name2(void) {
char name[4] = {'s','a','m','\0'};
printf("name is %s\n", name);
}
然后C语言的数组在初始化的时候是支持自动计算数组大小的,所以上面的代码还可以简化为:
void print_name3(void) {
char name[] = { 's','a','m','\0' };
printf("name is %s\n", name);
}
然后我们之前看到的双引号括起来的内容叫做 字符串常量 或叫做 字符串字面量 ,其进入编译器会自动加上 \0 字符。字符串常量用法如下:
void print_name4(void) {
char name[] = "sam";
printf("name is %s\n", name);
}
编译器在遇到字符串常量之后会将其存入内存,只存一次,存储在静态存储区。程序在遇到上面代码,会新建一个name数组,然后才实际将静态存储区里面的字符串常量数据拷贝过来。然后C语言还有一种利用指针的表示方法:
void print_name5(void) {
char * name = "sam";
printf("name is %s\n", name);
}
这个时候是将字符串常量的地址拷贝给指针,也就是内存里面并没有两个拷贝。
从上面的分析看的出来数组就是数组,指针就是指针,这并没有什么好纠结的,不过似乎大家总喜欢讨论数组名是不是指针,虽然在使用上似乎有一些相似,最简单的回答就是不是,数组名里面存放的地址是固定的,而指针里面存放的地址是可以随意变动的。没什么好纠结。
关于两种表达的选择,C primer plus给出的建议就是如果你的字符串需要修改操作,那么应该使用数组表达方式。
strlen函数
strlen函数由 <string.h> 包提供,它会返回字符串的长度,这里所说的长度是不包括 \0 这个字符的。
指针
指针是一个存储内存地址的变量。int类型存储的是整数,pointer类型存储的内存地址。指针声明如下:
int * p;
*表示该变量是个指针,int表示该指针指向的地址上的值是一个int值。
& 运算符是用于获得某个变量的内存地址; * 运算符用于根据某个内存地址或者指针名来获得该指针指向地址上的值。
C Primer Plus的这段说的非常的好:
普通变量把值作为基本量,把地址作为通过
&运算符获得的派生量;而指针把地址作为基本量,把值作为*运算符获得的派生量。
要深刻理解指针是个什么东西就是要知道假设我们有:
int x;
int* p = &x;
然后我们说
x = 2;
或者
*p = 2;
可以看做等价的语句。
当我们说某个指针指向某个变量,其暗含的意思即 *p 这个名字是 x 另外一个别名。也正是因为如此我们在C++后面会看到一种用法,本来某个类调用它的成员函数是 ABC->func ,该func函数名存储的该函数的地址实际上也可以看作一个指针量,只是不可变。假设你另外获知该类的该成员函数的地址,然后你这样调用也是一样的 ABC->*p_func 。
也正是因为如此我们会看到一些程序员喜欢这种写法 int *p ,他们把*和指针名放在一起潜台词就是*p 也就是一个类似于变量名 x,y之类的东西,只是它的名字前面多了一个星号。
swap_int函数
下面是指针讨论中非常经典的一个例子,那就是编写一个swap函数用于交换两个变量的值。
swap函数接受两个变量的值,然后交换这两个变量的值,这个函数在C语言里面的实现必须要用到指针。
void swap_int(int* p1, int* p2) {
// swap two int value
int temp;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main(void) {
int x = 2;
int y = 3;
swap_int(&x, &y);
printf("%d %d", x, y);
return 0;
}
这个函数从接受参数那里我们可以明显看到 int *p1 = &x 这样的操作,所以后面函数里面 *p1 实际上就是x这个东西了。
C语言这样处理是没有问题的,C++里面如果我们需要变量的别名这个概念,那么不应该使用指针,而应该使用引用变量。
引用变量
引用变量C++特有的概念,C语言是没有的,但我觉得现在引入引用变量这个概念正是时候。
引用变量就程序员编程的角度出发可以将其看作某个变量的别名,比如:
int a = 1;
int & b = a;
这样上面变量名a和b指向的都是同一块内存空间。
如果联系到上面的讨论,那么就是:
int x;
int & b = x;
实际上完成的就是上面的动作:
int x;
int* p = &x;
从而有*p 和x 和 b 都是一个东西。
下面是引用变量的swap_int版本
void swap_int(int& a, int& b) {
int temp;
temp = a;
a = b;
b = temp;
}
#include "myhead.h"
int main(void) {
int x = 2;
int y = 3;
swap_int(x, y);
printf("%d %d", x, y);
return 0;
}
函数的参数类型不管是指针也好还是引用变量也好,其效果都是直接使用调用环境外某个变量的原始值,如果只是希望使用某个值,则推荐是使用函数的参数的按指传递方式。但按指传递在很多情况下开销太大,于是const关键字在这种情况下是需要加上的。
数组
多维数组
C语言是直接支持用这样的形式 matrix[3][4] 来表示多维数组的,这个值得说明一下。
c
int x[3][2] = {
{1,2},
{1,2},
{1,2}
};
本来打算编写一个简单的函数先打印二维数组,然后竟发现还不是很方便。首先一维数组的情况怎么的都行,数组名你就可以看做一个指针:
void print_int_array(int* arr, int length) {
for (int i = 0; i < length; i++) {
printf("%d ", arr[i]);
}
}
int sum_int_array(int* arr, int length) {
int res = 0;
for (int i = 0; i < length; i++) {
res += arr[i];
}
return res;
}
二维数组就不存在这种数组名和指针的无缝转换了,你必须建立一种二维指针数组,这个过程引入了太多的复杂度,实在不是一个明智的选项;而且就算是这样你在建立函数的时候,二维数组的列数也必须写死。同时我又了解到 变长数组 的概念,但是这个 变长数组 visual studio 现在是不支持的,而且似乎也没有支持的计划,而且这个特性最新的C语言标准也是打算废弃的意思了。
此外我在 这个网页 了解到一种通过 malloc 函数 自动分配二维指针数组内存的方法,当然其内在本质还是依靠二维指针数组这个过于复杂的东西,个人不喜欢,尤其这种玩法还引入了 int ** p 这种东西,C语言的指针已经让大家很厌倦了,你还弄两个指针,显然这种玩法过于复杂现在不应该推荐了。
但还有一个解决方案,而这个方案利用的C语言的struct结构,个人觉得是优美的解决方案【也许你觉得里面的一维表达很丑,但实际上计算机内存里面存储的就是这种一维表达结构】。如果采取这种方案那么就应该抛弃C语言里面 x[3][2] 这样的表达,而回归一维数组的本源,然后继而可以扩展一些支持方法来进一步表达分组分行等内部属性。
typedef struct {
int rows;
int cols;
int data[0];
} Matrix2D;
void print_2d(Matrix2D* m) {
printf("[\n");
for (int i = 0; i < m->rows; ++i) {
printf(" [");
for (int j = 0; j < m->cols; ++j) {
printf("%3d ", m->data[i * m->cols + j]);
if (!(j == (m->cols-1))) {
printf(",");
}
else {
printf("]");
}
}
printf("\n");
}
printf("]\n");
}
#include "myhead.h"
int main(void) {
Matrix2D x = {
.rows = 3,
.cols = 4,
.data = { 1,2,3,4,5,6,7,8,9,10,11,12 }
};
print_2d(&x);
return 0;
}
结构体在函数中是可以直接传递地址过去的,因为数组名就是数组的首元素地址,一维数组直接传递数组名作为对象的指向指针也是没问题的。这里我们可以把结构体看做一种内部长度不一的一维数组形式,这样就可以理解为什么这样做是可行的。然后结构体的指针引用内部对象采用的是 m->cols 这样的写法。二维数组之所以不行是因为计算机只知道你传递过去的首元素地址和内部数据类型,但是具体几行几列这些信息是丢失了的。
Flexible array member in structure
本小节参看了 这篇文章 。上面结构体里面 int data[0] 是C99引入的新特性,叫做Flexible array member,其在一个结构体里面,而且其必须是结构体的最后一个成员。结构体除了lexible array member之外还必须有其他成员。
**NOTICE: 上面声明 int data[] 这种写法在visual studio那边可以,gcc按照默认的gnu11我试了只能是 int data[0] 这种写法才行。 **
再谈指针
正如前面谈论的,数组名就是数组的首元素地址,所以在编程中很多对于指针的操作都可以作用于数组名,只是说这个数组名相对于指针来说具体存储的内存地址是不可以变动了。指针的操作包括如下:
- 指针加一 具体内存地址偏移值是增加一个存储单元【一个数据对象】,对于int加4个字节,对于double加8个字节等【这里的讨论数值只是一个假设】。因为指针在声明的时候就包含了类型声明,所以指针偏移计算是知道具体我要偏移多少的。所以假设一个结构体指针加一,偏移值可能会比较大,具体就是偏移了一个结构体数据。
- 指针减一类似上面指针加一的讨论,就不赘述了。
- 所以利用数组名来进行某些编程中的指针偏移操作有的时候是很方便的,然后指针数组中的两个指向指针,相减得到的差的绝对值就是这个数组中这两个数据之间索引差。
个人觉得现代C语言代码的编写指针不要滥用了,但是对于数组名的某些操作,如上讨论的情况,是可以尽情使用的。
总之 arr[1] 和 *(arr+1) 是一个意思, arr[0] 和 *arr 是一个意思,知道这个就行了。
计算数组的长度
C语言里面涉及到数组的操作需要传递一个额外的长度参数,我们可以利用如下宏来将第二个参数的计算工作丢给程序。
#define SIZEOF(ARRAY) (sizeof(ARRAY)/sizeof(*ARRAY))
上面是一个带参数的宏,如下:
res = sum_int_array(y, SIZEOF(y));
将替换为:
res = sum_int_array(y, (sizeof(y)/sizeof(*y)));
这是没有问题的,不过如果上面的y改为结构体里面的数组似乎就不行了,这个和sizeof函数有关。不过就上面 Matrix2D 问题不大,rows*cols即可。
const来保护数组中的数据
因为数组在函数中传递的是指针,所以对于数组的修改动作就是修改原数组,如果你没有另外新建一个数组副本的话。但有的时候你需要保护某个数组里面的数据不被修改,那么可以通过修饰符 const 来做到这点。
int sum_int_array(const int* arr, int length)
字符串操作
puts和 gets_s函数
scanf在处理字符串的时候遇到空格就会停止,而gets函数可用于读取一整行的字符串输入,但现在不应该再使用gets函数了,因为如果用户输入行的字符串【这通常是未知的】超过了你在程序中声明的要存储的目的地的声明长度,就会导致缓冲区溢出错误。gets_s函数相当于安全版本的gets函数,下面是一个简单的演示例子:
#define LINE_MAX_LENGTH 100
int echo_line(void) {
char words[LINE_MAX_LENGTH];
puts("please input a line.");
gets_s(words, LINE_MAX_LENGTH);
puts(words);
return 0;
}
参考资料1 谈到行输入过长问题,利用fgets函数实现了一个函数,但是fgets更多的是针对文件io的读取操作,在这里就谈论的行输入问题有点大材小用了,最好是利用getchar函数来实现一个函数:
void empty_string(char* st, int length) {
// make target string fill with \0
// size is the target string char array length
for (int i = 0; i < length; i++) {
st[i] = '\0';
}
}
char* line_gets(char* st, int num) {
// here num is the max character number not include the \n
char ch;
int i = 0;
// make st is a empty string notice here need +1
empty_string(st, num+1);
ch = getchar();
while (ch != '\n') {
if (i < num) {
st[i] = ch;
}
else {
puts("your input line is too long, please input it again.");
// empty the previous user input buffer
while (getchar() != '\n') {
continue;
}
return line_gets(st, num);
}
i++;
ch = getchar();
}
return st;
}
#include "myhead.h"
int main(void) {
char words[5];
puts("please input a line.");
line_gets(words, 4);
puts(words);
return 0;
}
上面num的含义是字符不包括 \n 的长度,从用户的角度理解可以看做允许的可见字符数。
strcat函数
接受两个字符串参数,将后一个字符串附加到前一个字符串上,返回前一个字符串的指针,注意附加动作不要超过前一个字符串的容纳空间了。
strcmp函数
比较两个字符串的实际内容,多余的\0 会被容忍,如果内容相同则返回0,否则返回非0。
strcpy函数
接受两个字符串参数,将后一个字符串的内容拷贝到前一个字符串上,注意执行拷贝动作的时候内容不要超过前一个字符串的容纳空间了。
字符串排序
现在我们实现一个 strsort函数,其接受一个字符串数组参数和该数组的长度,内部动作将会把这个字符串数组进行排序。
void swap_pointer(void * p_1, void* p_2) {
// swap two pointer value
int* p1 = (int*)p_1;
int* p2 = (int*)p_2;
int* temp = NULL;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
void strsort(char* strings[], int num) {
for (int i=0; i < num; i++) {
for (int j = i + 1; j < num; j++) {
if (strcmp(strings[i], strings[j]) > 0) {
swap_pointer(&strings[i], &strings[j]);
}
}
}
}
#include "myhead.h"
int main(void) {
char st[] = "abcf";
char st2[] = "abcd";
char st3[] = "zzzz";
char st4[] = "eeee";
char* strings[] = { st, st2 ,st3, st4};
strsort(strings, SIZEOF(strings));
for (int i = 0; i < SIZEOF(strings); i++) {
puts(strings[i]);
}
return 0;
}
这里strcmp函数如果返回大于0的值意思是第一个字符串按照机器排序【并不是按照字母顺序排序】在后一个字符串前面。这只是一个临时排序方案,但在这里不是重点。上面的排序算法叫做选择排序,基本上就是一轮轮找序列最前面的值,将其放置在前面。
这里特别需要值得一提的一点就是 char * strings[] 严格的叫法应该叫做字符串指针数组,实际上在C语言里面并没有所谓的字符串数组的说法,因为字符串长度不一是不可能在C语言形成数组。所谓这个字符串指针数组实际上存储的一系列指针,也正是因为如此,上面试着实现了一种通用的交换两个指针的值得swap_pointer 函数。上面的空指针操作值得特别说明一下。
上面的例子如果直接用swap_int也是可以的,但那显然是不规范的,只是恰好int型可以存储指针罢了。然后直接写 strings[i] 也是可以的,那也是不规范的,只是打印字符串正常显示,但感到奇怪的是字符串也就是字符数组的指针指向是可以修改的,所以 char * st 和 char st[] 还真的没啥区别,不过程序员还是要自我约束下,就上面的例子来说从逻辑清晰的角度出发,必然是要传递指向字符串指针的地址进去的。
空指针
int* temp = NULL;
上面这一行是声明了一个指针,具体值是0【需要注意的是这里的0不是本指针在内存里面实际存储的位置,那是程序另外分配的】。
C语言在编写函数的时候可以如同上面这样声明 void * void类型指针:
void swap_pointer(void * p_1, void* p_2)
其可以接受随便指向什么类型的指针。但是在函数里面,接下来你需要针对这个空类型指针进行强制类型转换,否则无法使用:
int* p1 = (int*)p_1;
int* p2 = (int*)p_2;
就上面这个 swap_pointer 函数例子来说,int * 是随便选的,因为这里的操作都是针对指针实际存储的值,而不是指针映射的值。
进制转换例子
把字符串转成数字推荐使用 stdlib.h 的 strtol 函数【转成long类型】,或者 strtoul 函数【转成unsigned long类型】,或者 strtod 函数【转成double类型】。这些函数相比原 atoi 等函数更加的安全,而且该函数还可以指定进制位数。
这个例子引入一个问题,那就是函数如何返回字符串。C语言就字符串操作来说,如同上面strsort函数演示的,结果字符串指针可以传递进来,如下所示,这种方案是最简单的,也是最好的方案。
void number_radix_conversion(char* number, char * result, int input_radix, int output_radix) {
char* end;
unsigned long value;
value = strtoul(number, &end, input_radix);
if (output_radix == 2) {
_itoa(value, result, 2);
}
if (output_radix == 8) {
sprintf(result, "%o", value);
}
else if (output_radix == 10) {
sprintf(result, "%u", value);
}
else if (output_radix == 16) {
sprintf(result, "%x", value);
}
return result;
}
当然还有另外一种实现方法,那就是我们在函数内部新定义结果字符串,但是这就带来一个问题,那就是函数内部块声明的字符串定义,出了函数就是不可以访问了的,哪怕你返回该字符串的指针,因为C语言默认变量叫做自动变量,其访问权限是大家熟悉的编程语言的那种块作用域,而伴随着这种块作用域随之而来的是在内存管理上,该变量是被自动分配和释放的,简言之,就是大家熟悉的那种局部变量的概念。具体到这里函数内部声明的字符串,出了函数该字符串在内存里面也已经被清洗掉了,哪怕你有指针也只是在访问一个内存里面的莫名数据罢了。
下面我们看上面函数的第二个版本:
char * number_radix_conversion(char* number, int input_radix, int output_radix) {
char* end;
unsigned long value;
static char result[100];
value = strtoul(number, &end, input_radix);
if (output_radix == 2) {
_itoa(value, result, 2);
}
if (output_radix == 8) {
sprintf(result, "%o", value);
}
else if (output_radix == 10) {
sprintf(result, "%u", value);
}
else if (output_radix == 16) {
sprintf(result, "%x", value);
}
return result;
}
上面这个函数版本就真的实现了返回字符串,这个字符串是在函数内部声明的,之所以出了函数该字符串在内存里面没被清洗掉,是因为加上了 static 关键词,从而该result变量成了所谓的 静态变量 。静态变量在程序运行时内在内存里面是一直被保留而存在着的。
除了这个静态变量,C语言甚至可以跳出变量声明传统语法,直接指定内存我要多少空间。这个对内存的控制由浅到深是C语言的威力所在也是一把双刃剑,只有你真的明白了你在做什么,而且是除了这么做没有更好的方法,那么才可以这么做,如果默认的自动变量就能完成工作,是不应该纯粹为了炫技而编写那种代码的。
变量的作用域和存储类别
继续上面的讨论,C语言就变量作用域这块属于块作用域和文件作用域。for语句和函数和独立的花括号结构等都是一个区块。在区块内声明的变量可在本区块内直接访问,也就是直接使用该变量名即可。
但上面函数直接返回对函数内部某个变量的指针这就不属于直接访问了,我们现在假设那个变量还存在的话,那么是可以获得该变量的值的。上面例子的问题在于函数内部定义的某个变量在函数执行完之后就已经释放了,也就是那个变量已经不存在了。这就涉及到C语言里面的变量存储类别的讨论。
C语言的变量默认存储类别是auto,不作特别声明都是自动变量,该变量的存储管理是交给编译器的,也就是那个函数执行完了这个变量就被自动释放了。而上面声明该变量为static的意思是告诉编译器这个变量是一个静态变量,在程序运行期间请一直保留在内存里面。于是上面的程序就能正常运行了。
但是因为C语言的链接过程上的差异,会有一个更复杂的情况,比如下面这两个变量声明:
int giants = 5;
static int dodgers = 3;
int main(){
...
}
这两个变量都是文件作用域,所以giants和dodgers在本文件内都是可以直接访问的。又因为文件作用域不像函数作用域有一个内存释放机制,所以可以看作文件作用域变量都是静态存储的。所以对于C语言的文件作用域变量static意思并不是函数作用域的那个static的意思,标记了该变量是静态存储的,而只是标记了该变量的链接属性。 giants 在链接上是所有其他文件都是可以访问的,这个可以简单称作全局变量;而 dodgers 是只可以被本文件访问的,专业术语叫做内部链接。
还有一点值得一提,那就是上面的 dodgers 在其他文件里面如果如下声明:
extern int dodgers;
则该变量又成了外部链接的变量了, extern 声明是告诉编译器这个变量在其他地方声明的,我希望使用它。所以在程序链接的过程中就会有相应的处理。
上面提到的全局变量情况其他文件是可以直接使用的,但是一般的做法是推荐加上 extern 关键词,来增加程序的清晰性。
寄存器变量
register int c;
这里的寄存器变量声明是告诉C编译器这个变量会频繁用到,最好把它放入寄存器里面,仅仅只是加速用的,其他变量属性等同于 int c 。
malloc和free
malloc函数可以直接手工声明一个内存空间,要记得free该内存空间。这个本文暂时略过了,同样,只有在那种确实不得不使用malloc函数的情况才使用。
结构体
结构体的基本使用
结构体首先需要声明才能使用:
struct book{
char title[100];
char author[50];
};
这样声明之后,后面使用 struct book 就可以类似 int 一样声明相应的变量了:
int x;
struct book y;
结构体的变量的初始化如下所示:
struct book library = {
"this is a title",
"author",
};
此外C99和C11还提供了如下初始化语法:
struct book library = {
.title = "this is a title",
.author = "author",
};
访问结构体的成员变量采用 . 运算符:
library.title
library.author
在函数参数上你可以直接传递结构体或者传递结构体指针,传递结构体指针的时候你可以采用如下语法来访问结构体成员变量:
library->title
library->author
typedef
typedef 为某一类型声明一个别名,比如:
typedef unsigned char BYTE;
BYTE x;
typedef结合之前你定义的结构体类型会很好用:
typedef struct {
int rows;
int cols;
int data[];
} Matrix2D;
Matrix2D x;
链表
现在来实现LISP语言中常见的链表数据结构,本小节主要参考了 参考资料4 。就基本的结构定义写法还是很清晰的:
struct node{
int data;
struct node * next;
};
在上面的基础上,参考资料4做了一些灵活性拓展,个人做了一些修改于是有了下面的list.h 文件:
#ifndef LIST_H_
#define LIST_H_
#include <stdbool.h>
#define ItemType int
#define DefNode(NodeType, ListType) \
typedef struct node { \
ItemType item; \
struct node * next; \
}NodeType; \
typedef NodeType* ListType;\
DefNode(Node, List);
List init_list();
List make_list(ItemType x);
void print_list(List list);
void free_list(List* plist);
bool insert_list(ItemType x, List* plist);
bool is_list_empty(const List* plist);
unsigned int list_length(List list);
#endif
待参数的 #define 宏之前在介绍 SIZEOF 的时候提到了。然后 list.c 文件如下所示:
#include "list.h"
#include <stdio.h>
List make_list(ItemType x) {
// init_list with an item
List new_list;
new_list = (List)malloc(sizeof(Node));
new_list->item = x;
new_list->next = NULL;
return new_list;
}
List init_list() {
// init_list with no item
return NULL;
}
void print_list(List list) {
printf("\n[ ");
while (list != NULL) {
printf("%d, ", list->item);
list = list->next;
}
printf(" ]");
}
bool insert_list(ItemType x, List* plist) {
if ((*plist) == NULL) {
(*plist) = (List)malloc(sizeof(Node));
if (*plist == NULL) { // malloc failed.
return false;
}
(*plist)->item = x;
(*plist)->next = NULL;
return true;
}
else {
insert_list(x, &((*plist)->next));
}
}
bool is_list_empty(const List * plist) {
if (*plist == NULL) {
return true;
}
else {
return false;
}
}
unsigned int list_length(List list) {
unsigned int count = 0;
while (list != NULL) {
count++;
list = list->next;
}
return count;
}
void free_list(List* plist) {
/* NOTICE: assume all list is create by malloc
otherwise there will be a bug.
*/
Node* psave;
while ((*plist) != NULL)
{
psave = (*plist)->next;
free(*plist);
*plist = psave;
}
}
然后有运行文件:
#include "myhead.h"
#include "list.h"
int main(void) {
List list1 = make_list(1);
print_list(list1);
insert_list(2, &list1);
print_list(list1);
List list2 = init_list();
insert_list(3, &list2);
print_list(list2);
assert(list_length(list1) == 2);
free_list(&list1);
free_list(&list2);
return 0;
}
上面还有一些基本的链表操作动作函数没有实现,后续有时间补上。然后我们看到一旦你定义了一个你自己的数据结构,一般来说针对该数据结构的排序查找相关动作都要另外配套函数跟上。这就是面向对象编程风格的优点也是缺点。优点就是这些基础配套函数写好之后后面操作按照相应接口会很简单,缺点就是每引入一个新的对象或者数据结构,就会带来一系列的代码量和工作量,同时提升了整个项目的复杂度。
其他
enum
enum提供了一种枚举类型变量:
enum Color {red, green, blue};
enum Color color;
color = red;
比如上面的color就是一个枚举类型变量,其可以直接用red,green等这样的名字来赋值。具体red和green内部默认的是从0开始的整数。
union
联合 一种数据类型,其能在同一内存空间中存储不同的数据类型,比如:
union hold {
int digit;
double bigfl;
}
这个联合数据类型可以存储一个int类型或者一个double数据类型。具体分配内存空间是按照占用空间最大的数据类型来的。
命令行参数
int main(int argc, char * argv[]){
}
编写的程序如上编写接受命令行参数,argc是接受的参数个数,argv是参数字符串指针数组,其中argv[0] 为程序的名字,后面就是一些参数了。这种命令行参数的写法最好是对接大家都熟悉的通用接口, 这个Github项目 给出了一个实现版本。我做了一些简化。
即使简化之后就getopt里面的逻辑还是挺多的,但是还是需要使用这个和大家一致的刷参数的接口。
初看这个项目代码有些基本知识补充,比如头文件部分:
#ifdef what
...
#else
...
#endif
这是C语言预处理的条件编译语句。
#ifndef _WINGETOPT_H_
#define _WINGETOPT_H_
...
#endif
这是一种常用的让本宏包只加载一次的手段。
extern "C" {
...
}
这个声明是让C++以C的风格来处理这些声明。
统计文件字数程序
下面我们使用这个getopt刷参数函数来编写一个简单的模仿linux系统那边的wc命令行工具,主要提供三个参数选项: -c 打印字符数和 -l 打印行数和 -w 打印词数,然后必须通过 -f 指定输入文件。
下面这个例子也附带介绍了一下C语言里面文件是如何操作的,然后还有很多其他文件操作函数,比如 fprintf 函数还有之前提到过的 fgets 和 fputs 函数等等,这些简单了解一下即可。
#include "myhead.h"
#include "wingetopt.h"
int main(int argc, char* argv[]) {
char c;
char ch;
unsigned long char_count = 0;
unsigned long line_count = 0;
unsigned long word_count = 0;
extern char* optarg;
bool char_turn_on = false;
bool line_turn_on = false;
bool word_turn_on = false;
char* filename[100] = {[0]='\0'};
FILE* fp;
while ((c = getopt(argc, argv, "hclwf:")) != -1) {
switch (c) {
case 'h':
printf("Useage: wc [-clw] -f filename\n");
exit(EXIT_FAILURE);
case 'c':
char_turn_on = true;
break;
case 'l':
line_turn_on = true;
break;
case 'w':
word_turn_on = true;
break;
case 'f':
if (optarg == NULL) {
exit(EXIT_FAILURE);
}
else {
strcpy(filename, optarg);
break;
}
case '?':
printf("unknown option: 0%o\n", c);
break;
default:
exit(EXIT_FAILURE);
}
}
if (strlen(filename) == 0) {
printf("Need filename\n");
exit(EXIT_FAILURE);
}
if ((fp = fopen(filename, "r")) == NULL) {
printf("Can't open %s\n", filename);
exit(EXIT_FAILURE);
}
bool inword = false;
char prev;
while ((ch = getc(fp)) != EOF) {
// putc(ch,stdout );
if (char_turn_on) {
char_count++;
}
if (line_turn_on && ch == '\n') {
line_count++;
}
if (word_turn_on && !isspace(ch) && !inword) {
inword = true;
word_count++;
}
if (word_turn_on && isspace(ch) && inword) {
inword = false;
}
prev = ch;
}
if (prev != '\n') {
line_count++;
}
if (char_turn_on) {
printf("%s has %ld characters\n", filename, char_count);
}
if (line_turn_on) {
printf("%s has %ld lines\n", filename, line_count);
}
if (word_turn_on) {
printf("%s has %ld words\n", filename, word_count);
}
return 0;
}
C++版helloworld
#include <iostream>
int main(void) {
using namespace std;
cout << "hello world!";
cout << endl;
return 0;
}
头文件的扩展名
cpp新的风格头文件是没有扩展名的,比如 iostream 就是 iostream ,并没有.h或者.hpp之类的,这样可以使用 namespace std 。旧的风格大体类似于C语言带上 .h 后缀。
命名空间
这个算是和C语言很大的一个不同点了,命名空间这个概念对于熟悉编程的人来说并不是一个默认的概念了,大体类似于python的模块名,一些其他编程语言也有类似的概念。比如:
Microflot::hello("hello");
GooGloo::hello("hello");
上面一个是调用的命名空间Microflot里面的hello函数,另一个是调用的GooGloo命令空间的hello函数。之前的hello world程序 using namespace std; 的话就是如下写的:
#include <iostream>
int main(void) {
//using namespace std;
std::cout << "hello world!";
std::cout << std::endl;
return 0;
}
这个有点类似于python里面的 from what import * 将里面的函数名等都给导进来了,所以就可以直接使用cin,cout了。此外还有一种推荐的做法是:
using std::cout;
using std::endl;
这大体类似于python里面的 from what import cout ,只是具体导入了某个函数名之类的。
cout对象
cout是一个对象,其内部有方法知道如何打印字符串。
cout << "string";
上面代码的过程就是cout对象调用插入运算符 << ,从而执行某个操作将字符串插入到输出流中。
std::endl是一个特殊的C++符号 【换行符?】,将其插入输出流将导致屏幕光标换行。
cout << 25;
是的, cout可以直接打印int数值。
声明变量
cpp这点和c语言最大的区别是cpp是推荐在首次使用变量之前声明它而不是集中在文件开头。
#include <iostream>
int main(void) {
using namespace std;
int x;
int y;
cout << "please input the x value: ";
cin >> x;
cout << "please input the y value: ";
cin >> y;
cout << "x + y = " << x + y << endl;
return 0;
}
cin 和cout相比较之前C语言哪一套实在方便多了,然后我们看到cout可以进行简单的字符串拼接操作。
定义函数
#include <iostream>
int add(int a, int b) {
return a + b;
}
int add(int, int);
int main(void) {
using namespace std;
int x;
int y;
cout << "please input the x value: ";
cin >> x;
cout << "please input the y value: ";
cin >> y;
cout << "x + y = " << add(x,y) << endl;
return 0;
}
就cpp和c语言的函数定义和函数原型声明这块来说区别不是太大。熟悉C语言的这块简单温习下就好。
数据类型
整型有:short,int,long 和 long long 。一般没有有说服力的理由就应使用int。
char类型:char类型一般用于存储一个字节大小的字符,但也用于存储比short更小的整型。
bool类型:true or false
符号常量修饰符:const
浮点数类型:float、double、long double。
1.编写一个小程序,要求用户使用一个整数指出自己的身高(单位为英寸),然后将身高转换为英尺和英寸【这里的意思是取整部分为英尺余下部分继续为英寸】。该程序使用下划线字符来指示输入位置。另外,使用一个const符号常量来表示转换因子。
inch2foot.cpp
#include <iostream>
#include <cmath>
const int CONVERSION = 12;
int main(void) {
using namespace std;
int height_inch;
cout << "please input your height value in inch: ";
cin >> height_inch;
if (height_inch % CONVERSION == 0) {
cout << "your height value is " << height_inch / CONVERSION
<< " foots." << endl;
}
else {
cout << "your height value is " << height_inch / CONVERSION
<< " foots and " << height_inch % CONVERSION << "inchs." << endl;
}
return 0;
}
注解: % 是取模运算,整数之间的除法是取商运算。
3.编写一个程序,要求用户以度、分、秒的方式输入一个纬度,然后以度为单位显示该纬度。1度为60分,1分等于60秒,请以符号常量的方式表示这些值。对于每个输入值,应使用一个独立的变量存储它。下面是该程序运行时的情况:

to_degress.cpp
#include <iostream>
#include <cmath>
const float CONVERSION = 60;
int main(void) {
using namespace std;
int degrees;
int minutes;
int seconds;
float result;
cout << "Enter a latitude in degrees, minutes, and seconds:" << endl ;
cout << "First, enter the degrees: ";
cin >> degrees;
cout << "Next, enter the minutes of arc: ";
cin >> minutes;
cout << "Finally, enter the seconds of arc: ";
cin >> seconds;
result = degrees + minutes / CONVERSION + seconds / (CONVERSION * CONVERSION);
cout << degrees << " degrees, " << minutes << " minutes, " << seconds << " seconds = " <<
result
<< " degrees." << endl;
return 0;
}
注解: 本例主要演示了const定义常数项的用法。
5.编写一个程序,要求用户输入全球当前的人口和美国当前的人口(或其他国家的人口)。将这些信息存储在long long变量中,并让程序显示美国(或其他国家)的人口占全球人口的百分比。该程序的输出应与下面类似:

usa_population.cpp
#include <iostream>
#include <cmath>
int main(void) {
using namespace std;
long long word_population;
long long usa_population;
float population_ratio;
cout << "Enter the world's population: ";
cin >> word_population;
cout << "Enter the population of the US: ";
cin >> usa_population;
population_ratio = (float)usa_population / word_population * 100;
cout << "The population of the US is " << population_ratio << "% of the world population." << endl;
return 0;
}
注解: 本例主要演示了如何进行强制类型转换。
7.编写一个程序,要求用户按欧洲风格输入汽车的耗油量(每100公里消耗的汽油量(升)),然后将其转换为美国风格的耗油量—每加仑多少英里。注意,除了使用不同的单位计量外,美国方法(距离/燃料)与欧洲方法(燃料/距离)相反。100公里等于62.14英里,1加仑等于3.875升。因此,19mpg大约合12.4l/100km,27mpg大约合8.71/100km。
to_usa_mpg.cpp
#include <iostream>
#include <cmath>
int main(void) {
using namespace std;
float eu_fuel;
int usa_mpg;
const float KILOMETER_CONVERT_MILES = 0.6214;
const float GALLON_CONVERT_LITERS = 3.875;
cout << "Please input how many your car use fuel[unit liter] on running 100 kilometers: ";
cin >> eu_fuel;
usa_mpg = (int)(100 * KILOMETER_CONVERT_MILES) / (eu_fuel / GALLON_CONVERT_LITERS);
cout << "The mpg your car in usa standard is : " << usa_mpg << endl;
return 0;
}
long totals[500] = {0}; //初始化一个500个元素的数组,索引为0的元素设值为0,其他元素自动设值为0。
你也可以如下:
long totals[500] = {} ; // 这样所有元素都自动设值为0。
字符串类型,C严格意义上来说并没有所谓的字符串类型,C语言风格的字符串这里略过讨论了,C++添加了string类,你需要包含头文件string,然后就可以如下使用string类了。
string str1;
str1 = "abc";
熟悉C语言风格字符串使用的一下就看出一个巨大的区别了,那就是这里可以直接初始化字符串变量,不需要操作数组长度之类的东西了,非常好的改进!
然后C语言风格的字符串不可以将一个字符串的值赋值给另一个字符串,但是string类可以如下做:
string str1;
string str2 = "abc";
str1 = str2;
cout << str1 + str2;
你还可以用加法来进行字符串拼接,终于,类似python的那些基本字符串操作在C语言那边还要让人头疼好久这里终于顺畅一些了。
cout << str1.size(); // 返回3
请求行输入因为历史原因 cin.getline(charstr, max_size) 更接近于我们在C语言中熟知的那种概念,而友元函数 getline(cin, string) 反而更接近C++风格,因为cin是C++里面的概念,所以人们会预期cin的类方法会对接string接口,但这只是历史要兼容的原因罢了,并没什么特别的理由要弄得这样反常规。
C++里面的结构就基本的东西来说和C语言里面的讨论是没有太大区别的,C++里面的结构体当然也可以将string类作为成员对象。特别要强调的是C语言里面字符串数组实际上并没有所谓的字符串这个基本内存存储单元,因为字符串不定长,所以字符串数组实际下面存放的是指针,但是结构数组不同,C语言的结构体是如此基本,它就可以看做一个基本的内存存储单元,所以结构数组下面就是一个一个结构体而不是指向结构体的指针。因此结构体数组的引用语句是 struct_array[0].name 。
C++里面的Union和enum枚举和C语言里面的讨论也没有太大区别。
C++里面的指针还有相关内存管理malloc之类的等等和C语言里面的讨论也没有太大区别,不过需要注意的是C++编程一定程度上弱化了指针的概念,很多地方C++编程不一定要使用指针的,然后内存管理也不推荐使用malloc函数而是推荐使用new和delete运算符。
对于C++的基本类型和结构可以如下使用new来声明一个内存块,然后用给定的指针名来指向它,引用它和使用它。
typeName * pointer_name = new typeName;
int * pn = new int;
*pn = 1;
cout << *pn;
这个东西只能通过该指针来使用,参考资料1说这个东西更确切来说应该叫做数据对象,变量也是数据对象。不管怎么说,就是指内存里的那个东西。
delete运算符只能用于那些也就是上面讨论的new出来的指针。具体如下所示:
int * pn = new int;
delete pn;
使用new来创建数组和结构和其他又有所不同,以数组为例,常规声明数组叫做静态联编(static binding),即在编译阶段已经为该数组申请分配好内存了;而通过new来创建的数组只在后面运行阶段才可能创建,也就是运行阶段如果没使用这个数组也不会创建,这称为动态联编(dynamic binding)。这种数组叫做动态数组。
下面例子演示了其为何叫做动态数组,我们可以运行时用户指定该数组大小,然后运行时给定值:
#include <iostream>
#include <string>
int main(void) {
using namespace std;
int x;
cout << "please input the array length: ";
cin >> x;
int* parray = new int[x];
for (int i = 0; i < x; i++) {
cin >> parray[i];
}
for (int i = 0; i < x; i++) {
cout << parray[i] << endl;
}
delete[] parray;
return 0;
}
注意new出来的动态数组 delete 运算符语句加上了 [] 。
具体指针的使用C语言里面的东西了,这里可以回顾提醒一下, arr[1] 和 *(arr+1) 是一个意思, arr[0] 和 *arr 是一个意思。
关于指针和数组这块东西很多的,但因为都是C语言里面的知识点,我这里就略过讨论了,如果读者自觉在这块还有所欠缺,请在C语言教材对应的部分补习之。
也可以使用new一个动态的字符串,或者说动态字符数组,但这完全没有必要。因为string类内部也就是这样做的,你没必要去重复造轮子了,直接使用string类就是了。
使用new出来的结构参照前面的讨论,类似的叫做动态结构。这里的动态结构倒不是说结构的定义动态,结构体的定义还是要做的。
C语言里面就存储类型有自动存储和静态存储,简单来说自动存储变量的存活是程序自动管理的,而静态存储变量在整个程序运行期都是存活的。这一块C++和C语言是一致的,不同的是C++因为上面讨论的new运算符而提出了一个新的存储类型,叫做动态存储。具体new和delete运算符管理的内存池和静态变量和自动变量的内存池是分开的,其叫做自由存储空间或堆。如果new出来的动态存储变量没有delete,这叫做内存泄漏,内存泄露一般只是本程序那些内存没法用了,然后严重点本程序运行的内存被耗尽了,因为没有内存程序崩溃了。参考资料说这种严重的泄漏甚至导致操作系统或其他应用程序崩溃。
类似string类,C++用vector类来实现动态数组,类似上面的string类的讨论,如果你要自己利用new和delete来实现某种动态数组的效果,那么不要重复造轮子了,请用vector类,vector类内部就是这样做的。下面将上面动态数组的例子写成vector版本:
#include <iostream>
#include <string>
#include <vector>
int main(void) {
using namespace std;
int x;
cout << "please input the array length: ";
cin >> x;
vector<int> vec;
for (int i = 0; i < x; i++) {
int tmp;
cin >> tmp;
vec.push_back(tmp);
}
for (int i = 0; i < x; i++) {
cout << vec[i] << endl;
}
return 0;
}
vector类还有很多其他用法,但在这里不是重点。我们看到vector初始化不需要指定长度参数了,其通过push_back方法来新增元素。
vector类因为是动态数组,所以效率有点低,C++又实现了一个新的类array类,其内部存储和原来的数组存储风格一致,所以效率等价,然后因为是类,所有多了一些便捷的操作方法。这些方法后面有时间再慢慢了解。
编写一个C++程序,如下述输出示例所示的那样请求并显示信息:

注意,该程序应该接受的名字包含多个单词。另外,程序将向下调整成绩,即向下调一个字母。
xiti_c4_1.cpp
#include <iostream>
#include <string>
int main(void) {
using namespace std;
string first_name;
string last_name;
char grade;
int age;
cout << "What is your first name? ";
getline(cin, first_name);
cout << "What is your last name? ";
getline(cin, last_name);
cout << "What letter grade do you deserve? ";
cin.get(grade).get();
cout << "What is your age? ";
cin >> age;
cout << "Name: " << last_name << ", " << first_name << endl;
cout << "Grade: ";
cout.put(grade + 1);
cout << endl;
cout << "Age: " << age << endl;
return 0;
}
注解: 一般字符可以直接cout,但如果类型已经是int型了,那么希望输出对应的字符则需要使用cout.get。
编写一个程序,它要求用户首先输入其名,然后输入其姓;然后程序使用一个逗号和空格将姓和名组合起来,并存储和显示组合结果。请使用char数组和头文件cstring中的函数。下面是该程序运行时的情形:

xiti_c4_3.cpp
#include <iostream>
#include <cstring>
int main(void) {
using namespace std;
char first_name[20];
char last_name[20];
char name[40];
cout << "What is your first name? ";
cin.getline(first_name, 20);
cout << "What is your last name? ";
cin.getline(last_name,20);
strcpy_s(name, last_name);
strcat_s(name, ", ");
strcat_s(name, first_name);
cout << "Here's the information in a single string: " << name << endl;
return 0;
}
注解: 本例主要了解下C风格的字符数组用法。
结构CandyBar包含3个成员。第一个成员存储了糖块的品牌;第二个成员存储糖块的重量(可以有小数);第三个成员存储了糖块的卡路里含量(整数)。请编写一个程序,声明这个结构,创建一个名为snack的CandyBar变量,并将其成员分别初始化为“Mocha Munch”、2.3和350。初始化应在声明snack时进行。最后,程序显示snack变量的内容。
xiti_c4_5.cpp
#include <iostream>
#include <string>
using namespace std;
struct CandyBar {
string name;
float weight;
int calories;
};
int main(void) {
CandyBar snack = {
"Mocha Munch",
2.3,
350
};
cout << "CandyBar " << snack.name << " weight: " << snack.weight <<
" and calories: " << snack.calories << endl;
return 0;
}
注解: 本例主要演示了结构体的用法。
结构CandyBar包含3个成员,如上面讨论的。请编写一个程序,创建一个包含3个元素的CandyBar数组【使用new来动态分配数组,而不是声明一个包含3个元素的CandyBar数组】,并将它们初始化为所选择的值,然后显示每个结构的内容。
xiti_c4_6.cpp
#include <iostream>
#include <string>
using namespace std;
struct CandyBar {
string name;
float weight;
int calories;
};
int main(void) {
CandyBar* psnack = new CandyBar[3];
psnack[0].name = "aaa";
psnack[0].weight = 2.3;
psnack[0].calories = 5;
psnack[1] = {
"bbb",
2.5,
6
};
psnack[2] = {
"ccc",
2.6,
7
};
for (int i = 0; i < 3; i++) {
cout << "CandyBar " << psnack[i].name << " weight: " << psnack[i].weight <<
" and calories: " << psnack[i].calories << endl;
}
delete[] psnack;
return 0;
}
注解: 本例主要演示了如何new一个结构体。
William Wingate从事比萨饼分析服务。对于每个披萨饼,他都需要记录下列信息:
披萨饼公司的名称,可以有多个单词组成。 披萨饼的直径。 披萨饼的重量。 请设计一个能够存储这些信息的结构【请使用new来为结构分配内存,请使用vector来实现动态数组】,并编写一个使用这种结构变量的程序。程序将请求用户输入上述信息,然后显示这些信息。请使用cin(或它的方法)和cout。
xiti_c4_7.cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
struct Pizza {
string name;
float diameter;
float weight;
};
int main(void) {
int x;
cout << "please input the array length: ";
(cin >> x).get();
vector<Pizza *> vec;
for (int i = 0; i < x; i++) {
Pizza* ppizza = new Pizza;
cout << "Please input your pizza name: ";
getline(cin, ppizza->name);
cout << "Please input your pizza diameter: ";
(cin >> ppizza->diameter).get();
cout << "Please input your pizza weight: ";
(cin >> ppizza->weight).get();
cout << "-----------------" << endl;
vec.push_back(ppizza);
}
for (int i = 0; i < x; i++) {
cout << "CandyBar " << vec[i]->name << " weight: " << vec[i]->diameter <<
" and calories: " << vec[i]->weight << endl;
}
for (int i = 0; i < x; i++) {
delete vec[i];
}
return 0;
}
注解: 本例主要演示了vector的用法。
程序逻辑
这块C++和C语言内容基本上没什么区别,所以大多略过了,然后主要做一些习题也算是对前面学到的东西的再应用。
for range语句
c++11开始支持如下的for range语句了:
int a[] = {0, 1, 2, 3, 4, 5};
for (int n : a){
std::cout << n << ' ';
}
C++的for语句多了一个新的下面这种形式,这个要了解下:
for (int x: {1,2,3}){
cout << x;
}
这个熟悉python语言等高级语言的知道这是迭代遍历循环操作,然后后面可以是数组或者vector或者array。
关于cin的用法请看下面的演示例子,主要是这个补充知识点:cin.get获取字符之后返回的仍是cin对象,其如果在bool取值环境,如果读取成功则返回true,如果读取失败则返回fasle。读取失败也包括常规的EOF结尾情况。
#include <iostream>
int main() {
using namespace std;
char ch;
int count = 0;
cout << "Enter characters:\n";
while (cin.get(ch)) { //Ctrl+Z
cout << ch;
++count;
}
cout << endl << count << endl;
return 0;
}
1.编写一个要求用户输入两个整数的程序。该程序将计算并输出这两个整数之间(包括这两个整数)所有整数的和。这里假设先输入较小的整数。例如,如果用户输入的是2和9,则程序将指出2~9之间所有整数的和为44。
xiti_c5_1.cpp
#include <iostream>
int main() {
using namespace std;
int start_int;
int end_int;
int sum = 0;
cout << "please input the start integer: ";
cin >> start_int;
cout << "please input the end integer: ";
cin >> end_int;
for (int n = start_int; n <= end_int; n++) {
sum += n;
}
cout << "the integer in range " << start_int << " - " << end_int << " summation is " << sum << endl;
return 0;
}
注解: 本例主要演示了如何写for语句。
3.编写一个要求用户输入数字的程序。每次输入后,程序都将报告到目前为止,所有输入的累计和。当用户输入0时,程序结束。
xiti_c5_3.cpp
#include <iostream>
int main() {
using namespace std;
int temp;
int sum = 0;
do {
cout << "please input a number, input 0 quit : ";
cin >> temp;
sum += temp;
} while (temp);
cout << "your input number summation is " << sum << endl;
return 0;
}
注解: 本例演示了do-while语句。
5.假设要销售《C++ For Fools》一书。请编写一个程序,输入全年中每个月的销售量(图书数量,而不是销售额)。程序通过循环,使用初始化为月份字符串的char *数组(或string对象数组)逐月进行提示,并将输入的数据储存在一个int数组中。然后,程序计算数组中各元素的总数,并报告这一年的销售情况。
xiti_c5_5.cpp
#include <iostream>
int main() {
using namespace std;
int sum = 0;
string months[12] = { "jan","feb","march","april","may","june","july","august","september","october","november","december" };
int sales[12] = {};
int count = 0;
for (string month : months) {
cout << "please input the sale of amount in " << month << " : ";
cin >> sales[count];
count++;
}
for (int x : sales) {
sum += x;
}
cout << "this year's sale amount is: " << sum << endl;
return 0;
}
注解: 本例主要演示了如何使用新式的for语句。
6.完成编程练习5,但这一次使用一个二维数组来存储输入—3年中每个月的销售量。程序将报告每年销售量以及三年的总销售量。
xiti_c5_6.cpp
#include <iostream>
int main19() {
using namespace std;
int sum_all = 0;
string months[12] = { "jan","feb","march","april","may","june","july","august","september","october","november","december" };
int sales[3][12] = {};
for (int i = 0; i < 3; i++) {
int count = 0;
int sum_year = 0;
for (string month : months) {
cout << "please input year " << i << " the sale of amount in " << month << " : ";
cin >> sales[i][count];
sum_year += sales[i][count];
count++;
}
cout << "this year "<< i << "all sale amount is: " << sum_year << endl;
sum_all += sum_year;
}
cout << "the three year all sale amount is: "<< sum_all << endl;
return 0;
}
注解: 本例主要演示了二维数组的用法。
10.编写一个使用嵌套循环的程序,要求用户输入一个值,指出要显示多少行。然后,程序将显示相应行数的星号,其中第一行包括一个星号,第二行包括两个星号,依此类推。每一行包含的字符数等于用户指定的行数,在星号不够的情况下,在星号前面加上句点。该程序的运行情况如下:
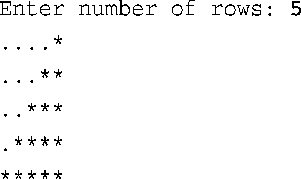
xiti_c5_10.cpp
#include <iostream>
int main20() {
using namespace std;
int rows;
cout << "Enter number of rows: ";
cin >> rows;
for (int i = 0; i < rows; i++) {
for (int j = i+1; j < rows; j++) { //here we can not use the if statement.
cout << ".";
}
for (int j = 0; j < i+1; j++) {
cout << "*";
}
cout << endl;
}
return 0;
}
注解: 需要注意本例不能使用if语句,所以才有上面的写法。
下面这个例子中 cin >> fish[i] 返回cin对象,其bool值含义是如果获取输入成功则返回true,如果获取输入失败则返回false。
cinfish.cpp
#include <iostream>
const int Max = 5;
int main() {
using namespace std;
double fish[Max];
cout << "fish #1: ";
int i = 0;
while (i < Max && cin >> fish[i]) {
if (++i < Max) {
cout << "fish #" << i + 1 << ": ";
}
}
double total = 0;
for (int j = 0; j < i; j++) {
total += fish[j];
}
if (i == 0) {
cout << "No fish\n";
}
else {
cout << "average weight is " << total / i;
}
return 0;
}
cinfish2.cpp
下面例子类似上面也是一个和用户交互请求输入数字的例子,不同的是上一个如果用户输入有误则退出,而这一个如果用户输入有误程序会继续请求用户输入。所以上一个例子是演示的不定数目的输入情况,而这一个演示的是如何处理用户输入有误时候的情况。为了和上面的例子进行比较我尽可能让这两个例子基本结构变动不大。
#include <iostream>
const int Max = 5;
int main() {
using namespace std;
double fish[Max];
cout << "fish #1: ";
int i = 0;
while (i < Max) {
while (!(cin >> fish[i])) { //failed for input
cin.clear();
while (cin.get() != '\n') { //clear the wrong input line
continue;
}
if (i < Max) {
cout << "fish #" << i + 1 << ": ";
}
}
i++;
if (i < Max) {
cout << "fish #" << i + 1 << ": ";
}
}
double total = 0;
for (int j = 0; j < i; j++) {
total += fish[j];
}
if (i == 0) {
cout << "No fish\n";
}
else {
cout << "average weight is " << total / i;
}
return 0;
}
注解: cin.clear() 是让cin在遇到错误输入之后可以继续开始接受输入。后面的while语句是清空缓存区那一行错误输入。
下面这个例子演示了如何写入文件:
outfile.cpp
#include <iostream>
#include <fstream>
int main() {
using namespace std;
char automobile[50];
int year;
double a_price;
double d_price;
ofstream outFile;
outFile.open("carinfo.txt");
cout << "Enter the make and modle of automobile: ";
cin.getline(automobile, 50);
cout << "Enter the model year: ";
cin >> year;
cout << "Enter the original asking price: ";
cin >> a_price;
d_price = 0.913 * a_price;
cout << fixed; //
cout.precision(2); //
cout.setf(ios_base::showpoint);
cout << "Make and modle: " << automobile << endl;
cout << "Year: " << year << endl;
cout << "Was asking $" << a_price << endl;
cout << "Now asking $" << d_price << endl;
outFile << fixed;
outFile.precision(2);
outFile.setf(ios_base::showpoint);
outFile << "Make and modle: " << automobile << endl;
outFile << "Year: " << year << endl;
outFile << "Was asking $" << a_price << endl;
outFile << "Now asking $" << d_price << endl;
outFile.close();
return 0;
}
具体在新建一个ofstream对象之后,通过open方法将输出流和目标文件联系起来,然后剩下来的动作和使用cout没有区别,最后记得把文件输出流调用close方法关闭。
ofstream outFile;
outFile.open("carinfo.txt");
....
outFile.close();
- precision方法 控制输出流浮点数的精度
setf(ios_base::showpoint)显示浮点数小数点后面的零
1.编写一个程序,读取键盘输入,直到遇到@符号为止,并回显输入(数字除外),同时将大写字符转换为小写,将小写字符转换为大写(别忘了cctype函数系列)。
xiti_c6_1.cpp
#include <iostream>
#include <cctype>
int main26() {
using namespace std;
char ch;
while (cin.get(ch)) {
if (ch == '@') {
break;
}
else if (isdigit(ch)) {
continue;
}
else if (isupper(ch)) {
cout.put(tolower(ch));
}
else if (islower(ch)) {
cout.put(toupper(ch));
}
else {
cout.put(ch);
}
}
return 0;
}
3.编写一个菜单驱动程序的雏形。该程序显示一个提供4个选项的菜单——每个选项用一个字母标记。如果用户使用有效选项之外的字母进行响应,程序将提示用户输入一个有效的字母,直到用户这样做为止。然后,该程序使用一条switch语句,根据用户的选择执行一个简单操作。该程序的运行情况如下:

xiti_c6_3.cpp
#include <iostream>
using namespace std;
void help();
void help() {
cout << "c) carnivore p) pianist\n" <<
"t) tree g) game\n";
}
int main() {
cout << "Please enter one of the following choices:\n";
help();
char ch;
(cin >> ch).get();
bool quit = false;
while (!quit) {
quit = true;
switch (ch) {
case 'c':
cout << "A maple is a carnivore";
break;
case 'p':
cout << "A maple is a pianist";
break;
case 't':
cout << "A maple is a tree";
break;
case 'g':
cout << "A maple is a game";
break;
default:
cout << "Please enter a c, p, t, or g: ";
(cin >> ch).get();
quit = false;
}
}
return 0;
}
5.在Neutronia王国,货币单位是tvarp,收入所得税的计算方式如下:
5000 tvarps:不收税
5001~15000 tvarps:10%
15001~35000 tvarps:15%
35000 tvarps以上:20%
例如,收入为38000 tvarps时,所得税为5000 0.00 + 10000 0.10 + 20000 0.15 + 3000 0.20,即4600 tvarps。请编写一个程序,使用循环来要求用户输入收入,并报告所得税。当用户输入负数或非数字时,循环将结束。
xiti_c6_5.cpp
#include <iostream>
int calc_tax(int);
int calc_tax(int x) {
float tax = 0;
int temp = 0;
temp = x - 35000;
if (temp > 0) {
tax += (temp * 0.2);
x -= temp;
}
temp = x - 15000;
if (temp > 0) {
tax += (temp * 0.15);
x -= temp;
}
temp = x - 5000;
if (temp > 0) {
tax += (temp * 0.10);
x -= temp;
}
return tax;
}
int main() {
using namespace std;
int tvarps = 0;
int count = 0;
do {
if (tvarps < 0) {
break;
}
if (count != 0) {
cout << "your income tax is " << calc_tax(tvarps) << " tvarps.\n";
}
count += 1;
cout << "please input how many tvarps of your income: ";
} while (cin >> tvarps);
return 0;
}
8.编写一个程序,它打开一个文件文件,逐个字符地读取该文件,直到到达文件末尾,然后指出该文件中包含多少个字符。
xiti_c6_8.cpp
#include <iostream>
#include <fstream>
int main() {
using namespace std;
string filename;
cout << "Please input the filename you want to open: ";
cin >> filename;
ifstream inFile;
inFile.open(filename);
// check the file is open
if (!inFile.is_open()) {
cout << "Could not open the file " << filename << endl;
exit(EXIT_FAILURE);
}
char ch;
int count = 0;
while (inFile.get(ch)) {
count++;
}
cout << "This file contains " << count << " characters.\n";
inFile.close();
return 0;
}
函数
我估计这块应该C++和C语言差异也不会太大,主要做一些习题练习下。
数组作为函数的参数
数组作为函数的参数实际传递的是该数组的首地址,但C++还需要知道这个数组内元素的类型,所以你在函数原型声明的时候应该类似这样进行声明: int sum_arr(int * arr, int n) ,或者 int sum_arr(int arr[], int n) ,这两种写法在函数原型声明上是没有区别的,告诉C++编译器该数组内的元素类型就完成任务了。如果函数不应该修改数组里面的内容,那么应该在声明前面加上 const 关键字。
可以通过下面这个例子来加深对数组作为函数的参数的理解:
arrfun.cpp
#include <iostream>
const int Max = 5;
int fill_array(double ar[], int limit);
void show_array(const double ar[], int size);
void revalue(double r, double ar[], int n);
double sum_array(const double* ar_begin, const double* ar_end);
int main(){
using namespace std;
double properties[Max];
int size = fill_array(properties, Max);
show_array(properties, size);
if (size > 0) {
cout << "Enter revaluation factor: ";
double factor;
while (!(cin >> factor)) {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input; Please enter a number: ";
}
revalue(factor, properties, size);
show_array(properties, size);
double total;
total = sum_array(properties, properties + size);
cout << "array total sum = " << total << " .\n";
}
return 0;
}
double sum_array(const double* ar_begin, const double* ar_end) {
const double* pt;
double total = 0;
for (pt = ar_begin; pt != ar_end; pt++) {
total += *pt;
}
return total;
}
int fill_array(double ar[], int limit) {
using namespace std;
double temp;
int i;
for (i = 0; i < limit; i++) {
cout << "Enter value #" << (i + 1) << ": ";
cin >> temp;
if (!cin) {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input; input process terminated.\n";
break;
}
else if (temp < 0) break;
ar[i] = temp;
}
return i;
}
void show_array(const double ar[], int size) {
using namespace std;
for (int i = 0; i < size; i++) {
cout << "Property #" << (i + 1) << ": $";
cout << ar[i] << endl;
}
}
void revalue(double r, double ar[], int n) {
for (int i = 0; i < n; i++) {
ar[i] *= r;
}
}
这个例子演示了基本的数组作为函数参数的使用方法,演示了const的使用,还演示了第二种数组作为函数参数的写法,具体请看sum_array函数,其接受的是数组的首地址和末地址,你可以通过 sum_array(properties, properties + size); 这种写法来传入数组的长度,或者随意计算数组前面几个元素的和都是可以的。
C风格字符串作为函数的参数
本质上C风格字符串属于字符数组,只是里面有个\0来标记字符串的结尾。具体使用参考上面的数组的讨论。
结构体作为函数的参数
结构体其实更加简单,其使用基本上可以看作某种额外的基本数据类型,你可以传值,也可以传指针,只是如果结构体比较大的话,还是推荐传指针。
关于C++新增的类的概念,比如string类,array类等,这些作为函数的参数大体可以参考结构体的使用,也就是可以看作某种额外的基本数据类型。关于类的使用后面会有更详细的讨论了。
函数作为函数的参数
函数名就是函数的地址,你可以直接将函数名作为参数传递进去,不过麻烦在这个函数指针的类型声明上:
void estimate(int repeat, double(*pf)(int));
声明的这个pf就是指向那个目标函数的指针,只是因为声明的时候要带上指向函数的类型声明,有的时候语句会很长。具体书写规则就是原函数类型声明,比如 double test_func(int) 然后将函数名换成 (*pf) 。
下面看一个例子:
#include <iostream>
using namespace std;
void estimate(int, double(*pf)(int));
double test_func(int a);
double test_func(int a) {
double b;
b = a * 3.14;
cout << a << " * 3.14 = " << b << endl;
return b;
}
void estimate(int repeat, double(*pf)(int)) {
for (int i = 0; i < repeat; i++) {
(*pf)(3);
}
}
int main() {
estimate(10, test_func);
return 0;
}
然后这种情况可以利用typedef进行简化:
typedef double(*test_func_type)(int);
这样typedef声明之后 test_func_type 就是具体某个函数的类型声明符了。
具体请看下面的样例来加深理解:
#include <iostream>
using namespace std;
typedef double(*test_func_type)(int);
void estimate(int , test_func_type);
double test_func(int a);
double test_func(int a) {
double b;
b = a * 3.14;
cout << a << " * 3.14 = " << b << endl;
return b;
}
void estimate(int repeat, test_func_type pf) {
for (int i=0; i < repeat; i++) {
(*pf)(3);
}
}
int main() {
estimate(10, test_func);
return 0;
}
1.编写一个程序,不断要求用户输入两个数,直到其中的一个为0。对于每两个数,程序将使用一个函数来计算它们的调和平均数,并将结果返回给main( ),而后者将报告结果。调和平均数指的是倒数平均值的倒数,计算公式如下:
调和平均数=2.0 * x * y / (x + y)
xiti_c7_1.cpp
#include <iostream>
#include <cctype>
using namespace std;
double calc_harmonic_mean(double, double);
double calc_harmonic_mean(double x, double y) {
double result;
result = (2.0 * x * y) / (x + y);
return result;
}
int main() {
double f1;
double f2;
double result;
while (true) {
if ((cout << "please input two number:") && (cin >> f1 >> f2)) {
bool input_line_right = true;
char ch;
while (cin.get(ch)) {
if (ch == '\n') {
break;
}
else if (isblank(ch)) {
;
}
else {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input!\n";
input_line_right = false;
break;
}
}
if (input_line_right) {
if (f1 == 0 || f2 == 0) break;
result = calc_harmonic_mean(f1, f2);
cout << f1 << " and " << f2 << " harmonic mean is: " << result << endl;
}
}
else {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input!";
}
}
return 0;
}
3.下面是一个结构声明:
struct box{
char maker[40];
float height;
float width;
float length;
float volume;
};
a.编写一个函数,按值传递box结构,并显示每个成员的值。
b.编写一个函数,传递box结构的地址,并将volume成员设置为其他三维长度的乘积。
c.编写一个使用这两个函数的简单程序。
xiti_c7_3.cpp
#include <iostream>
using namespace std;
typedef struct box {
char maker[40];
float height;
float width;
float length;
float volume;
}Box;
void show_box(Box box1);
void calc_box_volume(Box* pbox);
void show_box(Box box1) {
cout <<
"box: " << box1.maker << endl <<
"height: " << box1.height << endl <<
"width: " << box1.width << endl <<
"length: " << box1.length << endl <<
"volume: " << box1.volume
<< endl;
}
void calc_box_volume(Box* pbox) {
pbox->volume = pbox->width * pbox->height * pbox->length;
}
int main() {
//int main33() {
Box box1 = {
"box1",
2.5,
3.6,
7,
0
};
show_box(box1);
calc_box_volume(&box1);
show_box(box1);
return 0;
}
5.定义一个递归函数,接受一个整数参数,并返回该参数的阶乘。前面讲过,3的阶乘写作3!,等于3*2!,依此类推;而0!被定义为1。通用的计算公式是,如果n大于零,则n!=n*(n−1)!。在程序中对该函数进行测试,程序使用循环让用户输入不同的值,程序将报告这些值的阶乘。
xiti_c7_5.cpp
#include <iostream>
using namespace std;
int factorial(int);
int factorial(int x) {
if (x == 0) {
return 1;
}else {
return factorial(x - 1) * x;
}
}
int main() {
//int main34() {
int n;
int result;
while (true) {
if ((cout << "please input one integer number:") && (cin >> n)) {
bool input_line_right = true;
char ch;
while (cin.get(ch)) {
if (ch == '\n') {
break;
}
else if (isblank(ch)) {
;
}
else {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input!\n";
input_line_right = false;
break;
}
}
if (input_line_right) {
if (n < 0) break;
result = factorial(n);
cout << n << " factorial is: " << result << endl;
}
}
else {
cin.clear();
while (cin.get() != '\n') continue;
cout << "Bad input!\n";
}
}
return 0;
}
9.这个练习让您编写处理数组和结构的函数。下面是程序的框架,请提供其中描述的函数,以完成该程序。
#include <iostream>
using namespace std;
const int SLEN = 30;
struct student {
char fullname[SLEN];
char hobby[SLEN];
int ooplevel;
};
// getinfo has two arguments: a pointer to the first argument of
// an array of student structures and an int representing the
// number of elements of the array. the function solicits and
// stores data about students. It terminates input upon filling
// the array or upon encountering a blank line for the student
// name. the function returns the actual number of array elements
// filled.
int getinfo(student pa[], int n);
// display1 takes a student structure as an argument
// and display its contents.
void display1(student st);
// display2 takes the address of students structure as an
// argument and display the structure's cntents.
void display2(const student* ps);
// display3 takes the address of the first element of an array
// of student structures and the number of array elements as
// arguments and displays the contents of the structures
void display3(const student pa[], int n);
int main() {
//int main35() {
cout << "Enter class size: ";
int class_size;
cin >> class_size;
while (cin.get() != '\n') continue;
student* ptr_stu = new student[class_size];
int entered = getinfo(ptr_stu, class_size);
for (int i = 0; i < entered; i++) {
display1(ptr_stu[i]);
display2(&ptr_stu[i]);
}
display3(ptr_stu, entered);
delete[] ptr_stu;
cout << "Done\n";
return 0;
}
xiti_c7_9.cpp
#include <iostream>
#include <cstring>
using namespace std;
const int SLEN = 30;
struct student {
char fullname[SLEN];
char hobby[SLEN];
int ooplevel;
};
int getinfo(student pa[], int n);
void display1(student st);
void display2(const student* ps);
void display3(const student pa[], int n);
int getinfo(student pa[], int n) {
int entered = 0;
for (int i = 0; i < n; i++) {
cout << "please input student fullname: ";
cin.getline(pa[i].fullname, SLEN);
cout << "please input student hobby: ";
cin.getline(pa[i].hobby, SLEN);
cout << "please input student ooplevel: ";
(cin >> pa[i].ooplevel).get();
entered += 1;
}
return entered;
}
void display1(student st) {
cout <<"student " << st.fullname <<
" hobby: " << st.hobby <<
" ooplevel: " << st.ooplevel << endl;
}
void display2(const student* ps) {
cout <<"student " << ps->fullname <<
" hobby: " << ps->hobby <<
" ooplevel: " << ps->ooplevel << endl;
}
void display3(const student pa[], int n) {
for (int i = 0; i < n; i++) {
display1(pa[i]);
}
}
int main() {
//int main35() {
cout << "Enter class size: ";
int class_size;
cin >> class_size;
while (cin.get() != '\n') continue;
student* ptr_stu = new student[class_size];
int entered = getinfo(ptr_stu, class_size);
for (int i = 0; i < entered; i++) {
display1(ptr_stu[i]);
display2(&ptr_stu[i]);
}
display3(ptr_stu, entered);
delete[] ptr_stu;
cout << "Done\n";
return 0;
}
10.设计一个名为calculate( )的函数,它接受两个double值和一个指向函数的指针,而被指向的函数接受两个double参数,并返回一个double值。calculate( )函数的类型也是double,并返回被指向的函数使用calculate( )的两个double参数计算得到的值。例如,假设add( )函数的定义如下:
double add(double x, double y){
return x + y;
}
则下述代码中的函数调用将导致calculate( )把2.5和10.4传递给add( )函数,并返回add( )的返回值(12.9):
double q = calculate(2.5, 10.4, add)
请编写一个程序,它调用上述两个函数和至少另一个与add( )类似的函数。该程序使用循环来让用户成对地输入数字。对于每对数字,程序都使用calculate( )来调用add( )和至少一个其他的函数。如果读者爱冒险,可以尝试创建一个指针数组,其中的指针指向add( )样式的函数,并编写一个循环,使用这些指针连续让calculate( )调用这些函数。提示:下面是声明这种指针数组的方式,其中包含三个指针:
double (*pf[3])(double, double);
可以采用数组初始化语法,并将函数名作为地址来初始化这样的数组。
xiti_c7_10.cpp
#include <iostream>
using namespace std;
typedef double (*func_call)(double, double);
double addition(double , double );
double subtraction(double, double);
double multiplication(double, double);
double calculate(double x, double y, func_call func);
double calculate(double x, double y, func_call func) {
return (*func)(x, y);
}
double addition(double x, double y) {
cout << "running addition...\n";
return x + y;
}
double subtraction(double x, double y) {
cout << "running subtraction...\n";
return x - y;
}
double multiplication(double x, double y) {
cout << "running multiplication...\n";
return x * y;
}
int main() {
double (*pf[3])(double, double);
pf[0] = addition;
pf[1] = subtraction;
pf[2] = multiplication;
for (int i : {0, 1, 2}) {
double q = calculate(2.5, 10.4, pf[i]);
cout << "result: " << q << endl;
}
return 0;
}
函数补充
接下来的内容多是C++特有的内容了。
内联函数
内联函数和普通函数的区别就是在函数定义或声明的时候加上关键字 inline ,具体实现上的区别就是普通函数编译出来的代码函数有一个跳转执行的过程,而内联函数的代码与调用该函数的代码是内联在一起的,并没有这个跳转动作。
可以把内联函数比作C语言中的宏定义的函数,比如C++的:
inline double square(double x){return x * x};
可以比作C语言的:
#define SQUARE(X) ((X)*(X))
引用变量用于结构体和类大体逻辑可以参考上面的讨论,值得一提的是返回结构体和类采用相关的返回引用变量的形式将是高效的,不像传统返回值还需要额外的拷贝动作。
struct free_throws{
string name;
int made;
}
free_throws & accumulate(free_throws & target, const free_throws & source){
...
return target;
}
默认参数
方法就是在函数原型声明的时候如下给定默认参数,具体函数定义实现那里不用变。
int harpo(int n, int m=4, int j = 5);
函数重载
函数重载或函数多态具体来说就是几个函数拥有相同的函数名,不同的参数数目或类型,C++编译器会匹配合适的对应的那个函数。在匹配过程中不会考虑 const 关键字。这种匹配是基于函数的原型声明,不会考虑具体形参的名字。这种匹配不会考虑具体函数的返回类型。
函数模板
C++的函数模板运行你以一种泛型的概念来编写函数:
template <typename AnyType>
void swap(AnyType & a, AnyType & b){
AnyType temp;
temp = a;
a = b;
b = temp;
}
模板函数同样也存在重载。这里情况会稍微有点复杂,以C++98标准来说,具体化类型版本是优先于模板版本的:
template <> void swap(job &, job &);
template <typename T>
void swap(T &, T &);
但这块里面东西还有很多,暂时略过了,有时间可以了解下,感觉这个东西就和运算符优先级问题一样,实在不行加个括号,这里也是实在不行改个函数名就是了。
1.编写通常接受一个参数(字符串的地址),并打印该字符串的函数。然而,如果提供了第二个参数(int类型),且该参数不为0,则该函数打印字符串的次数将为该函数被调用的次数(注意,字符串的打印次数不等于第二个参数的值,而等于函数被调用的次数)。是的,这是一个非常可笑的函数,但它让您能够使用本章介绍的一些技术。在一个简单的程序中使用该函数,以演示该函数是如何工作的。
xiti_c8_1.cpp
#include <iostream>
using namespace std;
inline void print_string(string& s) { cout << s; }
void print_string(string& s, int n );
void print_string(string& s, int n) {
if (n <= 0) return;
for (int i = 0; i < n; i++) {
print_string(s);
}
}
int main() {
//int main37() {
string s = "abc";
print_string(s,10);
return 0;
}
2.CandyBar结构包含3个成员。第一个成员存储candy bar的品牌名称;第二个成员存储candy bar的重量(可能有小数);第三个成员存储candy bar的热量(整数)。请编写一个程序,它使用一个这样的函数,即将CandyBar的引用、char指针、double和int作为参数,并用最后3个值设置相应的结构成员。最后3个参数的默认值分别为“Millennium Munch”、2.85和350。另外,该程序还包含一个以CandyBar的引用为参数,并显示结构内容的函数。请尽可能使用const。
xiti_c8_2.cpp
#include <iostream>
#include <cstring>
using namespace std;
const int SLEN = 50;
struct CandyBar {
char name[SLEN];
double weight;
int calories;
};
CandyBar& init_CandyBar(CandyBar& candybar, const char * name="Millennium Munch", double weight=2.85, int calories=350);
void print_CandyBar(const CandyBar& candybar);
CandyBar& init_CandyBar(CandyBar& candybar, const char * name, double weight, int calories) {
strcpy_s(candybar.name, SLEN, name);
candybar.weight = weight;
candybar.calories = calories;
return candybar;
}
void print_CandyBar(const CandyBar& candybar) {
cout << "candybar name: " << candybar.name <<
" weight: " << candybar.weight << " calories: " << candybar.calories;
}
int main() {
//int main38() {
CandyBar candybar;
init_CandyBar(candybar);
print_CandyBar(candybar);
return 0;
}
因为是指明要用char指针,所以才这样实现,如果用string的话会简单很多。
5.编写模板函数max5( ),它将一个包含5个T类型元素的数组作为参数,并返回数组中最大的元素(由于长度固定,因此可以在循环中使用硬编码,而不必通过参数来传递)。在一个程序中使用该函数,将T替换为一个包含5个int值的数组和一个包含5个dowble值的数组,以测试该函数。
xiti_c8_5.cpp
#include <iostream>
#include <assert.h>
using namespace std;
template <typename T>
T max5(T arr[]);
template <typename T>
T max5(T arr[]) {
T max = arr[0];
for (int i = 0; i < 5; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}
int main() {
int arr1[5] = {45,54,1,8,0 };
int max1 = 0;
max1 = max5(arr1);
assert(max1 == 54);
double arr2[5] = { 5.58,6.5,0,3.14,1.25 };
double max2 = 0;
max2 = max5(arr2);
assert(max2 == 6.5);
return 0;
}
这题还是很简单的,就是基本的模板函数用法,我们继续看下面这题。
6.编写模板函数maxn( ),它将由一个T类型元素组成的数组和一个表示数组元素数目的整数作为参数,并返回数组中最大的元素。在程序对它进行测试,该程序使用一个包含6个int元素的数组和一个包含4个double元素的数组来调用该函数。程序还包含一个具体化,它将char指针数组和数组中的指针数量作为参数,并返回最长的字符串的地址。如果有多个这样的字符串,则返回其中第一个字符串的地址。使用由5个字符串指针组成的数组来测试该具体化。
xiti_c8_6.cpp
#include <iostream>
#include <assert.h>
#include <cstring>
using namespace std;
template <typename T>
T maxn(T arr[], int n);
template <> char* maxn(char* arr[], int n);
template <typename T>
T maxn(T arr[], int n) {
T max = arr[0];
for (int i = 0; i < n; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}
template<> char * maxn(char * arr[], int n) {
char * max = arr[0];
for (int i = 0; i < n; i++) {
if (strlen(arr[i]) > strlen(max)) {
max = arr[i];
}
}
return max;
}
int main() {
//int main40() {
int arr1[6] = {-5, 45,54,1,8,0 };
int max1;
max1 = maxn(arr1,6);
assert(max1 == 54);
double arr2[4] = { 5.58,6.5,3.14,1.25 };
double max2;
max2 = maxn(arr2,4);
assert(max2 == 6.5);
char s1[] = "abc";
char s2[] = "abc def";
char s3[] = "";
char s4[] = "hello world.";
char s5[] = "a";
char* arr3[5] = {s1,s2,s3,s4,s5 };
char* max3;
max3 = maxn(arr3, 5);
assert(strlen(max3) == 12);
return 0;
}
函数模板的显示具体化具体函数部分编写和常规函数相比就是多了 template <> 这个东西,然后注意原型声明上有这样的顺序:
- 一般常规函数
- 模板函数
- 模板函数具体化
然后具体重载顺序C++98给定的顺序是一般常规函数最优先,模板函数具体化优先于模板函数。
内存模型和名称空间
头文件常包含的内容:
- 函数原型
- 使用
#define或const定义的符号常量 - 结构声明
- 类声明
- 模板声明
- 内联函数
关于多文件编译相关知识在之前的C语言学习中已经讨论过了,这块并没有什么区别。
内存模型
所谓内存模型实际上就是在讨论C++语言的变量内存生存期问题。变量的作用域和生存期是两个问题,要正常访问一个变量首先当然这个变量应该是存在的,也就是这个变量是在生存期的,其次就是这个变量是可访问的,也就是当前变量代码所在是处于该变量的作用域的。
C++和C语言在变量的作用域问题上其实和其他大多数编程语言差别都不大,只是你有时可能会遇到一些奇怪的术语,但程序员都懂的,可以简单把C++或C语言理解为花括号分区块的块作用域语言。
C++和C语言和其他高级编程语言可能多了一个变量内存生存期问题。其他高级编程语言变量生存期可能都是由程序自动管理的,这个在C++或C语言里面对应的叫做自动存储变量。继而C语言引入了 static 关键字和静态存储变量这个概念,简单来说静态存储变量在整个程序运行期都是存活的【再一次强调变量存活和可访问是两回事,你在一个文件里面声明的全局静态变量在其他文件是不可以访问的,继而C语言提出了文件作用域的概念,但个人觉得没必要再增加一个额外的作用域的概念,这个情况只是因为静态变量要正常访问还需要编译器链接的时候做一些额外的动作,具体就是其他文件使用extern声明。原则上其他文件使用某个文件上定义的变量,不管是静态变量还是自动变量都应该使用extern关键字声明一下变量,只是说静态变量的情况是一定要声明,否则用不了,而自动变量的情况是你不声明就可以直接用,声明了反而会报错。】。
C++再继而又提出了一个内存存储类型,这个之前在介绍 new 关键字的时候讨论过,叫做动态存储。具体就是new和delete运算符管理的内存池和静态变量和自动变量的内存池是分开的,其叫做自由存储空间或堆。
此外C++还提出了一种线程存储类型,具体是 thread_local 关键字引入进来,这个本文应该会较少讨论。
关于这块如果C语言相关知识和前面关于new关键字的讨论部分真的学懂了的话,那么本小节内容大概了解下即可。
名称空间
C++的名称空间这个概念并不难理解,主要是为了防止各个库之间命名冲突用的。比如下面:
namespace Jack{
void fetch();
}
namespace Jill{
void fetch();
}
在命名空间外面要想使用对应的函数的话要使用 Jill::fetch() 这种格式;而在命名空间里面则直接使用即可。
如果你使用了 using Jill::fetch; ,则后面可以直接使用 fetch 来代替 Jill:fetch 。这个专业术语叫做using声明。
using namespace Jill 这种写法我们早就看到过了,就是把Jill名称空间下的变量名都引入进来。这个专业术语叫做using编译。
using声明是不能导入相同的名字,而使用using编译,则情况有些例外。具体要看你使用using编译在那里,比如下面这种情况:
namespace Jill{
void fetch();
}
char fetch;
int main(){
using namespace Jill;
...
}
using编译这时引入叫做引入了局部名称空间,说的再直白点就是这里引入的Jill名称空间里面的变量都在main函数里面,是main函数里面的局部变量。你在main函数里面说我要使用fetch则就是对应的 Jill::fetch ,但全部变量或者说全部名称空间的那个fetch还是可以访问的,具体要采用这样的形式: ::fetch 。
一般是推荐使用using声明,using编译只是为了方便。
命名空间可以如下嵌套:
namespace abc{
namespace def{
int i;
}
}
上面int i 的引用完整表达是: abc::def::i 。
未命名的命名空间:
namespace {
int ice;
}
未命名的命名空间有点像外面的全局变量一样可以::ice 来引用,但区别在于其不能使用using语句,也就是这里面的变量只是本文件可见的。
命令空间的样例程序请参看 test_namesp.cpp 和 namesp.h 和namesp.cpp这三个文件。
1.下面是一个头文件:
//golf.h
const int Len = 40;
struct golf{
char fullname[Len];
int handicap;
};
// non-interactive version:
// function sets golf structure to provided name, handicap
// using values passed as arguments to the function
void setgolf(golf & g,const char * name, int hc);
// interactive version:
// function solicits name and handicap from user
// and sets the members of g to the values entered
// returns 1 if name is entered, 0 if name is empty string
int setgolf(golf & g);
// function resets handicap to new value
void handicap(golf & g, int hc);
// function displays contents of golf structure
void showgolf(const golf & g);
注意到setgolf( )被重载,可以这样使用其第一个版本:
golf ann;
setgolf(ann, "Ann Birdfree", 24);
上述函数调用提供了存储在ann结构中的信息。可以这样使用其第二个版本:
golf ann;
setgolf(ann);
上述函数将提示用户输入姓名和等级,并将它们存储在andy结构中。这个函数可以(但是不一定必须)在内部使用第一个版本。
根据这个头文件,创建一个多文件程序。其中的一个文件名为golf.cpp,它提供了与头文件中的原型匹配的函数定义;另一个文件应包含main( ),并演示原型化函数的所有特性。例如,包含一个让用户输入的循环,并使用输入的数据来填充一个由golf结构组成的数组,数组被填满或用户将高尔夫选手的姓名设置为空字符串时,循环将结束。main( )函数只使用头文件中原型化的函数来访问golf结构。
golf.h大体类似上面定义的。
golf.cpp
#include <iostream>
#include "golf.h"
#include <cstring>
void setgolf(golf& g, const char* name, int hc) {
strcpy_s(g.fullname, name);
g.handicap = hc;
}
int setgolf(golf& g) {
using std::cout;
using std::cin;
cout << "please input name: ";
cin.getline(g.fullname, Len);
if (strlen(g.fullname) == 0) return 0;
cout << "please input handicap: ";
(cin >> g.handicap).get();
return 1;
}
void handicap(golf& g, int hc) {
g.handicap = hc;
}
void showgolf(const golf& g) {
using std::cout;
using std::endl;
if (strlen(g.fullname) > 0) {
cout << g.fullname << "'s handicap is: " << g.handicap << endl;
}
}
xiti_c9_1.cpp
#include <iostream>
#include "golf.h"
int main() {
const int ARR_MAX = 10;
golf golf_arr[ARR_MAX];
int res = 1;
for (int i = 0; i < ARR_MAX; i++) {
if (res == 0) break;
if (i == 0) {
setgolf(golf_arr[i], "bob sam", 10);
}
else {
res = setgolf(golf_arr[i]);
}
showgolf(golf_arr[i]);
}
std::cout << "test handicap function....\n";
showgolf(golf_arr[0]);
handicap(golf_arr[0], 18);
showgolf(golf_arr[0]);
return 0;
}
本习题主要是要求读者掌握多文件C++的编写过程。
4.请基于下面这个名称空间编写一个由3个文件组成的程序:
namespace SALES{
const int QUARTERS = 4;
struct Sales{
double sales[QUARTERS];
double average;
double max;
double min;
};
// copies the lesser of 4 or n items from the array ar
// to the sales member of s and computes and stores the
// average, maximum, and minimum values of the entered items;
// remaining elements of sales, if any, set to 0;
void setSales(Sale & s, const double ar[], int n);
// gathers sales for 4 quarters interactively, stores them
// in the sales member of s and computes and stores the
// average, maximum, and minimum values.
void setSales(Sale & s);
// display all information in structure s
void showSales(const Sales & s);
}
第一个文件是一个头文件,其中包含名称空间;第二个文件是一个源代码文件,它对这个名称空间进行扩展,以提供这三个函数的定义;第三个文件声明两个Sales对象,并使用setSales( )的交互式版本为一个结构提供值,然后使用setSales( )的非交互式版本为另一个结构提供值。另外它还使用showSales( )来显示这两个结构的内容。
sales.cpp
#include <iostream>
#include "sales.h"
namespace SALES {
void calcSales(Sales& s) {
double max = s.sales[0];
double min = s.sales[0];
double sum = 0;
double average = 0;
int i;
for (i = 0; i < 4; i++) {
if (s.sales[i] < min) {
min = s.sales[i];
}
if (s.sales[i] > max) {
max = s.sales[i];
}
sum += s.sales[i];
}
average = sum / 4;
s.average = average;
s.max = max;
s.min = min;
}
void setSales(Sales & s, const double ar[], int n) {
int i;
for (i = 0; i < 4; i++) {
if (n > 0) {
s.sales[i] = ar[i];
n--;
}
else {
s.sales[i] = 0;
}
}
calcSales(s);
}
void setSales(Sales & s) {
using std::cout;
using std::cin;
for (int i = 0; i < 4; i++) {
cout << "please input QUARTERS " << i + 1 << " sales: ";
(cin >> s.sales[i]).get();
}
calcSales(s);
}
void showSales(const Sales & s) {
using std::cout;
using std::endl;
for (int i = 0; i < 4; i++) {
cout << "QUARTERS " << i+1 << " sales: " << s.sales[i] << endl;
}
cout << "average: " << s.average << endl;
cout << "maximum: " << s.max << endl;
cout << "minimum: " << s.min << endl;
}
}
xiti_c9_4.cpp
#include <iostream>
#include "sales.h"
int main() {
double ar[4] = { 1.0,3.2,2.5,5.6 };
using SALES::Sales;
using SALES::setSales;
using SALES::showSales;
Sales s;
setSales(s, ar, 4);
showSales(s);
Sales s2;
setSales(s2);
showSales(s2);
return 0;
}
本习题主要要求读者掌握名称空间的用法。
类
下面进入C++语言区别C语言引入的最大特性,那就是类和相关面向对象编程的概念。本文假定读者已经熟悉一门高级编程语言比如python了,所以就面向对象编程相关概念不会做过多的讨论,预先假定读者已经对这一块很熟悉了。下面我们来看C++类是如何声明的:
class Stock
{
private:
std::string company;
long shares;
double share_val;
void set_tot(){total_val = shares * share_val;}
public:
void acquire(const std::string & co, long n, double pr);
}
上面出现的一个新的概念就是 private 和 public 这两个区块定义了该类的私有变量和公有变量,私有变量是不可以直接访问的变量【这里所谓的变量也包括函数名】,而公有变量是该类可以直接访问的变量。在其他高级编程语言中也会出现类似的概念,只是一些语言不是强制要求,只是作为编程规范提及。这里需要提醒读者的是私有变量不光是出于安全方面的考虑,很多时候一些数据仅仅出于类和软件系统架构上的设计,出于便捷易用性也会考虑隐藏某些数据而只提供必要的接口给外界使用。
由于类的变量属性默认就是private,所以实际编程可以考虑不写这个private,只在公有变量部分声明public即可。
类方法的具体实现就是编写函数,只不过其函数名字要写成这样的形式:
void Stock::acquire(const std::string & co, long n, double pr)
{
// your function
}
类作用域
类里面定义的变量具体在C++里面作用域又新增一个概念,叫做类作用域,因为类的声明本身包含一个花括号区块,这个倒不是出人意料之外。你可以把类作用域看作另外一个花括号区块来理解其中的变量作用域关系,然后需要特别强调的是类作用域之内的变量是可以直接调用——这里强调的是类的成员函数里面是可以直接使用类里面的各个变量,因为C++的类的成员函数具体定义是在外面的分开的,所以这里强调下。
static
在类作用域下static变量和前面谈论的函数作用域下的static变量大体含义是类似的,但因为类class和实例object的关系,需要细讲一下。请看下面这个例子:
#include <iostream>
using namespace std;
class StopWatch
{
public:
static int NoOfInstances;
StopWatch()
{
NoOfInstances++;
}
};
int StopWatch::NoOfInstances = 0;
int main() {
StopWatch sw1;
StopWatch sw2;
cout << StopWatch::NoOfInstances << endl;
StopWatch sw3;
StopWatch sw4;
cout <<StopWatch::NoOfInstances << endl;
return 0;
}
class定义声明了一个static变量,这个变量是为class和各个实例共有的。其和其他静态变量一样统一管理的,然后就是类里面的静态变量声明和实现是分开的,除非声明的时候加上const关键词则可以直接初始化,否则后面还需要加上这样格式的初始化语句:
int StopWatch::NoOfInstances = 0;
构造函数
创建Stock对象在面向对象编程有专门的说法叫做创建Stock实例,如下所示:
Stock sally;
sally.hello();
上面语句就是创建了一个Stock实例Sally,然后调用了sally内的hello方法。
读者从C语言学到这里可能觉得 Stock sally 有点类似于声明了一个结构体,没什么好奇怪的,但如果已经熟悉了面向对象编程的,听到这里说 Stock sally 这一句就创建了一个Stock实例内心就会生出一些困惑的。他会想因为类有时很复杂,实例化需要通过一个实例化初始函数来完成一些工作,他会想是不是有 Stock() 这个东西,他想的没有错。
C++在面向对象编程这块概念上和其他高级语言其实差别不大,C++的所有类的实例化同样要经过一个实例化函数,只是C++这边专业术语叫做构造函数,C++的类实例化都要调用这个构造函数的,如果你没有定义,那么将调用默认的构造函数。
比如上面的 Stock sally 其属于隐式调用默认构造函数,其等于 Stock sally = Stock() 。构造函数的定义如下:
Stock::Stock(const std::string & co, long n, double pr)
{
//
}
此外C++还有一种隐式调用构造函数的形式:
Stock sally(...)
其等于:
Stock sally = Stock(...)
析构函数
析构函数简单来说就是该对象即将过期时最后要调用的成员函数,其功能可以类比python类的 __del__ 方法。析构函数的写法如下:
Stock::~Stock()
{
//
}
构造函数和析构函数同样如下在头文件中声明下:
class Stock
{
....
public:
Stock();
~Stock();
...
}
this指针
C++这个this指针的概念可以类比python的self ,而且这个this参数在C++的类方法里面还是作为默认参数传递进去的,也就是直接用就是了,其代表的就是对本实例的一个指针。注意this是一个指针,其调用内部成员要使用 this->a 这样的语法。
关于返回 *this 有点让人困惑,请参看 这个网页 ,其和方法或说成员函数的返回声明类型有关,如果是声明的 Stock & 则 *this 是对本实例的引用,一个引用变量 ;否则返回的是本对象的一个复制。
const成员函数
class Stack{
...
public:
double total() const;
}
前面提到this指针,本实例作为参数是隐含传递进去了,如果希望该成员函数不修改调用对象也就是本实例的数据,则可以用上面的写法,成员函数后面跟一个const,具体术语叫做const成员函数,这样该const成员函数是不会修改本实例的数据的。
类内定义的数组长度是常量的情况
如下类里面定义一个数组,其长度是一个常量,下面的写法是错误的 【参考资料1提到类里面定义常量都要使用enum或者static const形式我是存有疑问的,因为个人实践一般const设置的常量只要不是数组情况也是可以正常使用的。】。
class Stack{
const int MAX=3;
double costs[MAX];
}
这是因为类的声明还只是描述类的形式,还并没有实际进行实例化创建动作。而后面要进行这种创建动作的要找这个MAX的值却发现找不到了。你可以使用enum枚举,因为枚举只是一个符号名称,代码编译时已经自动替换为某个数值了。
class Stack{
enum {MAX = 3};
double costs[MAX];
}
或者创建一个静态常量:
class Stack{
staic const int MAX=3;
double costs[MAX];
}
下面请参考 test_stack.cpp 这个例子来详细理解前面的内容。
2.下面是一个非常简单的类定义:
#include <string>
class Person {
private:
static const int LIMIT = 25;
std::string lname;
char fname[LIMIT];
public:
Person() { lname = ""; fname[0] = '\0'; };
Person(const std::string& ln, const char* fn = "Heyyou");
void Show() const; // firstname lastname format
void FormalShow() const; // lastname firstname format
};
它使用了一个string对象和一个字符数组,让您能够比较它们的用法。请提供未定义的方法的代码,以完成这个类的实现。再编写一个使用这个类的程序,它使用了三种可能的构造函数调用(没有参数、一个参数和两个参数)以及两种显示方法。下面是一个使用这些构造函数和方法的例子:
Person one;
Person two("Smythecraft");
Person three("Dimwiddy", "Sam");
one.Show();
cout << endl;
one.FormalShow();
//etc for two and three person
上面 Person() { lname = ""; fname[0] = '\0'; }; 这种在声明时就写上成员函数的定义的函数会自动成为内联函数。你也可以如下按照传统inline方法来写:
class Person{
...
public:
Person();
}
inline Person::Person(){
lname = "";
fname[0] = '\0';
}
像C++这种额外的写法,那些不重要的语法糖性质的东西我不会在介绍语言特性的正文中引入,必要时提到即可。
本例子主要检验了读者对本章节前面关于类的编写的一些基本知识和应用。
person.h
#include "person.h"
#include <iostream>
Person::Person(const std::string& ln, const char* fn ) {
strcpy_s(this->fname, fn);
this->lname = ln;
}
void Person::Show() const {
std::cout << this->fname << " " << this->lname << std::endl ;
}
void Person::FormalShow() const {
std::cout << this->lname << " " << this->fname << std::endl;
}
xiti_c10_2.cpp
#include <iostream>
#include "person.h"
int main() {
using namespace std;
Person one;
Person two("Smythecraft");
Person three("Dimwiddy", "Sam");
one.Show();
cout << endl;
one.FormalShow();
two.Show();
cout << endl;
two.FormalShow();
three.Show();
cout << endl;
three.FormalShow();
return 0;
}
3.重做前面xiti_c9_1 编程,但要用正确的golf类声明替换那里的代码。用带合适参数的构造函数替换 setgolf(golf &, const char *, int),以提供初始值。保留 setgolf( ) 的交互版本,但要用构造函数来实现它(例如,setgolf( )的代码应该获得数据,将数据传递给构造函数来创建一个临时对象,并将其赋给调用对象,即 *this )。
在golf.h那里新增Golf类的声明:
class Golf {
private:
static const int Len = 40;
char fullname[Len];
int handicap;
public:
Golf();
Golf(const char* name, int hc);
void showgolf();
void set_handicap(int hc);
};
在Golf.cpp那里新增Golf类的定义:
Golf::Golf() {
using std::cout;
using std::cin;
cout << "please input name: ";
cin.getline(this->fullname, Len);
if (strlen(this->fullname) != 0) {
cout << "please input handicap: ";
(cin >> this->handicap).get();
}
}
Golf::Golf(const char* name, int hc) {
strcpy_s(this->fullname, name);
this->handicap = hc;
}
void Golf::showgolf() {
using std::cout;
using std::endl;
if (strlen(this->fullname) > 0) {
cout << this->fullname << "'s handicap is: " << this->handicap << endl;
}
}
void Golf::set_handicap(int hc) {
this->handicap = hc;
}
xiti_c10_3.cpp
#include <iostream>
#include "golf.h"
int main() {
Golf golf1 = Golf("bob sam", 10);
golf1.showgolf();
Golf golf2 = Golf();
std::cout << "test handicap function....\n";
golf2.showgolf();
golf2.set_handicap(18);
golf2.showgolf();
return 0;
}
本例也算是对结构体和类之间转换的一种思考,结构内的访问属性默认是public,而类里面的变量默认访问属性是private。C++程序员该使用类就会使用类,而结构体只是某种纯粹的数据表达。
6.下面是一个类的声明:
class Move{
private:
double x;
double y;
public:
Move(double a = 0, double b = 0); // set x,y to a,b
void showmove() const; //show current x,y values
Move add(const Move & m) const;
// this function adds x of m to x of invoking object to get new x,
// add y of m to y of invoking object to get new y, create a new
// move object initialized to new x,y values and returns it.
void reset(double a = 0, double b = 0); //reset x,y to a,b
};
请编写该类的成员函数定义和具体测试该类的程序。
move.cpp内容如下:
#include "move.h"
#include <iostream>
Move::Move(double a, double b) {
this->x = a;
this->y = b;
}
void Move::showmove() const {
using std::cout;
cout << "<Move x=" << this->x << " y=" << this->y << ">\n";
}
Move Move::add(const Move& m) const {
double new_x = this->x + m.x;
double new_y = this->y + m.y;
return Move(new_x, new_y);
}
void Move::reset(double a, double b) {
this->x = a;
this->y = b;
}
xiti_c10_6.cpp
#include <iostream>
#include "move.h"
int main() {
//int main48() {
Move m1 = Move();
m1.showmove();
Move m2 = Move(3, 5);
Move m3 = Move(2.2, 5.0);
Move m4 = m3.add(m2);
m4.showmove();
m4.reset(9.8, 0);
m4.showmove();
return 0;
}
8.可以将简单列表描述成下面这样:
- 可存储0或多个某种类型的列表;
- 可创建空列表;
- 可在列表中添加数据项;
- 可确定列表是否为空;
- 可确定列表是否为满;
- 可访问列表中的每一个数据项,并对它执行某种操作。
可以看到,这个列表确实很简单,例如,它不允许插入或删除数据项。
请设计一个List类来表示这种抽象类型。您应提供头文件list.h和实现文件list.cpp,前者包含类定义,后者包含类方法的实现。您还应创建一个简短的程序来使用这个类。
该列表的规范很简单,这主要旨在简化这个编程练习。可以选择使用数组或链表来实现该列表,但公有接口不应依赖于所做的选择。也就是说,公有接口不应有数组索引、节点指针等。应使用通用概念来表达创建列表、在列表中添加数据项等操作。对于访问数据项以及执行操作,通常应使用将函数指针作为参数的函数来处理:
void visit(Item (*pf)(Item &));
其中,pf指向一个将Item引用作为参数的函数(不是成员函数),Item是列表中数据项的类型。visit( )函数将该函数用于列表中的每个数据项。
list.h 内容如下:
#pragma once
#ifndef LIST_H_
#define LIST_H_
#define ItemType double
typedef ItemType(*func_type)(ItemType&);
class List {
private:
enum { MAX = 10 };
ItemType items[MAX];
int num;
public:
List(); // default empty list
bool is_full() const;
bool is_empty() const;
void show_list()const;
void append(ItemType item);
void visit(func_type pf);
};
#endif // !LIST_H_
list.cpp
#include "list.h"
#include <iostream>
List::List() {
num = 0;
}
bool List::is_full() const {
if (num == MAX) {
return true;
}
else {
return false;
}
}
bool List::is_empty() const {
if (num == 0) {
return true;
}
else {
return false;
}
}
void List::show_list() const {
using std::cout;
cout << "[";
for (int i = 0; i < num; i++) {
cout << items[i] << ", ";
}
cout << "]\n";
}
void List::append(ItemType item) {
using std::cout;
if (!is_full()) {
items[num++] = item;
}
else {
cout << "list is full.";
}
}
void List::visit(func_type pf) {
for (int i = 0; i < num; i++) {
items[i] = (*pf)(items[i]);
}
}
xiti_c10_8.cpp
#include <iostream>
#include "list.h"
ItemType multiply2(ItemType& item) {
return item * 2;
}
int main() {
List list1 = List();
list1.show_list();
list1.append(10);
list1.append(20);
list1.show_list();
list1.visit(multiply2);
list1.show_list();
return 0;
}
本例只要求实现一个简单的列表,其中函数作为参数部分也算是一个温习。
运算符重载
类相应的运算符重载在python那边是在类里面重新定义 __add__ 之类的方法,而在C++这边是重新定义 operator+ 之类的这样的成员函数,然后就重载了对应的运算符操作。具体这块细节后面有时间再慢慢熟悉,本文也是接触到什么运算符就提到相关知识点,不会面面俱到的,在这块学习上是没必要要求面面俱到的。
请看下面的例子:
mytime.h
#pragma once
#ifndef MYTIME_H_
#define MYTIME_H_
#include <iostream>
class MyTime {
private:
int hours;
int minutes;
public:
MyTime();
MyTime(int h, int m = 0);
void AddMin(int m);
void AddHr(int h);
void Reset(int h = 0, int m = 0);
MyTime operator+(const MyTime & t) const;
MyTime operator-(const MyTime& t) const;
MyTime operator*(double mult) const;
friend MyTime operator*(double m, const MyTime& t) { return t * m; };
friend std::ostream & operator<<(std::ostream& os, const MyTime& t);
void Show()const;
};
#endif // !MYTIME_H_
mytime.cpp
#include "mytime.h"
#include <iostream>
MyTime::MyTime() {
hours = 0;
minutes = 0;
}
MyTime::MyTime(int h, int m) {
hours = h;
minutes = m;
}
void MyTime::AddMin(int m) {
minutes += m;
hours += minutes / 60;
minutes %= 60;
}
void MyTime::AddHr(int h) {
hours += h;
}
void MyTime::Reset(int h, int m) {
hours = h;
minutes = m;
}
MyTime MyTime::operator+(const MyTime& t) const {
MyTime sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes / 60;
sum.minutes %= 60;
return sum;
}
MyTime MyTime::operator-(const MyTime& t) const {
MyTime diff;
int tot1, tot2;
tot1 = t.minutes + 60 * t.hours;
tot2 = minutes + 60 * hours;
diff.minutes = (tot2 - tot1) % 60;
diff.hours = (tot2 - tot1) / 60;
return diff;
}
MyTime MyTime::operator*(double mult) const {
MyTime result;
long total = hours * mult * 60 + minutes * mult;
result.minutes = total % 60;
result.hours = total / 60;
return result;
}
std::ostream& operator<<(std::ostream& os, const MyTime& t) {
os << t.hours << " hours, " << t.minutes << " minutes";
return os;
}
void MyTime::Show()const {
std::cout << hours << " hours, " << minutes << " minutes";
}
test_mytime.cpp
#include <iostream>
#include "mytime.h"
int main() {
//int main50(){
using std::cout;
using std::endl;
MyTime planning;
MyTime coding(4, 35);
MyTime fixing(2, 55);
MyTime total;
MyTime diff;
MyTime adjusted;
MyTime adjusted2;
cout << "planning time = ";
planning.Show();
cout << endl;
cout << "coding time = ";
coding.Show();
cout << endl;
cout << "fixing time = ";
fixing.Show();
cout << endl;
total = coding + fixing;
cout << "coding + fixing = ";
total.Show();
cout << endl;
diff = coding - fixing;
cout << "coding - fixing = ";
diff.Show();
cout << endl;
adjusted = coding * 1.5;
cout << "coding * 1.5 = ";
adjusted.Show();
cout << endl;
adjusted2 = 1.5 * coding ;
cout << "1.5 * coding = ";
cout << adjusted2 << endl;
return 0;
}
这个例子演示了重载目标MyTime类的加法减法和乘法,然后具体时间刻度计算了解下即可。倒是这里面代码中的这一行:
MyTime sum;
sum.minutes = minutes + t.minutes;
让我困惑,然后我认识到之前对于 private 个人理解是有所偏差的。如果是类的成员函数,调用自身私有变量,在同一个类的作用域中,可以直接调用这是可以理解的。而这里是另外新建了一个MyTime对象可以直接调用私有变量这是我没有想到的。如果是其他类的对象,当然是不能直接调用私有变量的,否则这个私有变量设定就没有意义了,这里显然是本类的对象,在本类的成员函数定义里面,是可以直接调用私有变量的。
友元函数
在上面的例子中,对象乘以1.5这样的操作直接重载 operator* 即可,但是如果是 1.5 * coding 这样的形式,这个时候需要重载一般意义上的乘法,但如果只是一般重载乘法传过来的该类对象的私有变量是不可以直接访问的,而这个时候就需要使用友元函数,具体声明形式如下:
friend MyTime operator*(double m, const MyTime& t);
其实际上并不是类的成员函数,但也是写在类的声明里面的,前面要加上 friend 关键字,然后其对于MyTime也就是本类的访问权限和成员函数是一样的。上面完整的形式是:
friend MyTime operator*(double m, const MyTime& t) { return t * m; };
也就是一个内联函数,再利用原有的 operator* 即可。
同样类似的下面还重载了 << 运算符,好让该对象支持cout直接输出:
friend std::ostream & operator<<(std::ostream& os, const MyTime& t);
具体实现:
std::ostream& operator<<(std::ostream& os, const MyTime& t) {
os << t.hours << " hours, " << t.minutes << " minutes";
return os;
}
注意返回了原ostream 对象,为的是支持 cout << a << b 这样的形式。
下面继续下一个例子,模拟物理上的矢量运算:
vector.h
#pragma once
#ifndef VECTOR_H_
#define VECTOR_H_
#include <iostream>
namespace VECTOR {
class Vector {
public:
enum Mode{RECT, POL};
// RECT rectangular mode POL polar mode
private:
double x;
double y;
double mag;
double ang; // unit is radian
Mode mode;
void set_mag();
void set_ang();
void set_x();
void set_y();
public:
Vector();
Vector(double n1, double n2, Mode form = RECT);
void reset(double n1, double n2, Mode form = RECT);
~Vector();
double xval() const { return x; };
double yval() const { return y; };
double magval() const { return mag; };
double angval() const { return ang; };
void polar_mode();
void rect_mode();
//operator overloading
Vector operator+(const Vector& b) const;
Vector operator-(const Vector& b) const;
Vector operator-()const;
Vector operator*(double n)const;
//friends
friend Vector operator*(double n, const Vector& a);
friend std::ostream& operator<<(std::ostream& os, const Vector& v);
};
}
#endif // !VECTOR_H_
vector.cpp
#include <cmath>
#include "vector.h"
using std::sqrt;
using std::sin;
using std::cos;
using std::atan;
using std::atan2;
using std::cout;
namespace VECTOR {
const double Rad_to_deg = 45/atan(1);
void Vector::set_mag() {
mag = sqrt(x * x + y * y);
}
void Vector::set_ang() {
if (x == 0.0 && y == 0.0) {
ang = 0.0;
}
else {
ang = atan2(y, x);
}
}
void Vector::set_x() {
x = mag * cos(ang);
}
void Vector::set_y() {
y = mag * sin(ang);
}
Vector::Vector() {
x = y = mag = ang = 0;
mode = RECT;
}
Vector::Vector(double n1, double n2, Mode form) {
mode = form;
if (mode == RECT) {
x = n1;
y = n2;
set_mag();
set_ang();
}
else if (form == POL) {
mag = n1;
ang = n2 / Rad_to_deg; // input n2 is degree
set_x();
set_y();
}
else {
cout << "Incorrect 3rd argument to Vector() -- ";
cout << "vector set to 0\n";
x = y = mag = ang = 0;
mode = RECT;
}
}
void Vector::reset(double n1, double n2, Mode form) {
mode = form;
if (mode == RECT) {
x = n1;
y = n2;
set_mag();
set_ang();
}
else if (form == POL) {
mag = n1;
ang = n2 / Rad_to_deg;
set_x();
set_y();
}
else {
cout << "Incorrect 3rd argument to Vector() -- ";
cout << "vector set to 0\n";
x = y = mag = ang = 0;
mode = RECT;
}
}
Vector::~Vector() {
}
void Vector::polar_mode() {
mode = POL;
}
void Vector::rect_mode() {
mode = RECT;
}
Vector Vector::operator+(const Vector& b)const {
return Vector(x + b.x, y + b.y);
}
Vector Vector::operator-(const Vector& b)const {
return Vector(x - b.x, y - b.y);
}
Vector Vector::operator*(double n)const {
return Vector(n * x, n * y);
}
Vector operator*(double n, const Vector& a) {
return a * n;
}
Vector Vector::operator-() const{
return Vector(-x, -y);
}
std::ostream& operator<<(std::ostream& os, const Vector& v) {
if (v.mode == Vector::RECT) {
os << "(x,y) = (" << v.x << ", " << v.y << ")";
}
else if (v.mode == Vector::POL) {
os << "(m,a) = (" << v.mag << ", " << v.ang * Rad_to_deg << ")";
}
else {
os << "Vector object mode is invalid.";
}
return os;
}
}
test_vector.cpp
#include <iostream>
#include "vector.h"
int main() {
//int main51(){
using std::cout;
using std::endl;
using VECTOR::Vector;
Vector v1;
Vector v2(4, 3);
Vector v3(2, 5);
Vector v4;
Vector v5;
Vector v6;
Vector v7;
Vector v8;
cout << "v1 = " << v1 << endl;
v4 = v2 + v3;
cout << "v4 = " << v4 << endl;
v4.reset(9, 8);
cout << "v4 = " << v4 << endl;
v5 = -v4;
cout << "v5 = " << v5 << endl;
v6.reset(10, 45, VECTOR::Vector::POL);
cout << "v6 = " << v6 << endl;
v6.rect_mode();
cout << "v6 = " << v6 << endl;
v7 = 2 * v5 ;
cout << "v7 = " << v7 << endl;
v8 = v7 - v6;
cout << "v8 = " << v8 << endl;
return 0;
}
- 弧度的换算是根据 $atan(1) = \frac{\pi}{4}$ ,从而得到常见的换算公式1弧度等于 $\frac{180}{\pi}$ 。
- ang默认单位是radian
- 构造函数和reset方法都好理解,然后坐标为极坐标是第二个参数输入角度单位是度。
- 对于加减乘运算的重载,其写法很优雅地利用了构造函数,从而根据构造函数默认的xy坐标很方便进行一些运算并自动计算得到极坐标的相关数据。
- cout的输出方法并不是很难理解,倒是这个
if (v.mode == Vector::RECT) {不可以直接使用RECT值得引起我们的注意,这是一个友元函数,其和该类的成员函数具有相同的访问权限,但只是访问权限,这里是作用域问题。这是因为: 友元函数不在类作用域中。之所以没有加上 VECTOR是因为该友元函数在namespace VECTOR里面,但是不可以直接使用 RECT。
参考资料1的随机漫步那个例子就不列出来,这不是这里讨论的重点。
类的类型转换
将其他类型数据转成本类
将其他类型数据转成本类利用的就是本类的构造函数。其中有隐式转换和显示转换两种。个人不太喜欢类的类型的隐式转换,不太推荐编程的时候使用太多这种类型隐式转换,会让你的程序晦涩难懂并可能失控。具体隐式转换是如下面写法:
Stonewt myCat;
myCat = 19.6;
C++会试着查找Stonewt类的构造函数,然后发现构造函数有:
Stonewt(double lbs);
这个特征参数匹配,就会试着调用 Stonewt(19.6) 来进行隐式类型转换。个人不太喜欢这种写法,而实际上C++也不推荐这种写法,并引入了 explicit 关键词:
explicit Stonewt(double lbs);
这个构造函数引入explicit关键词之后就不能用于隐式类型转换了,如果需要类型转换,则必须采用如下明确的形式:
Stonewt myCat;
myCat = Stonewt(19.6);
这种写法也更明确易懂。
将本类转成其他类型数据
下面只讲明确的显示类型转换情况,具体就是本类需要编写类似operator int() 这样的成员函数。
比如:
Stonewt::operator int()const{
return int(pounds + 0.5);
}
然后实际使用就是这种 (int) what 形式即返回目标类型数据。再一次,一般转换函数推荐加上 explicit 关键词:
class Stonewt{
explicit operator int () const;
}
这样禁用掉隐式转换,推荐写代码时都写成显示转换的形式,这样代码也更明确易懂一些。
1.请参考下面的randwalk.cpp 代码,对其进行修改,使之将一系列连续的随机漫步者位置写入到文件中。对于每个位置,用步号进行标示。另外,让该程序将初始条件(目标距离和步长)以及结果小结写入到该文件中。该文件的内容与下面类似:

randwalk.cpp
#include <iostream>
#include <cstdlib> // rand srand
#include <ctime> //time
#include "vector.h"
int main() {
using namespace std;
using VECTOR::Vector;
srand(time(0)); // time(0) the current time, srand reset random seed.
double direction;
Vector step;
Vector result(0.0, 0.0);
unsigned long steps = 0;
double target;
double dstep;
cout << "Enter target distance (q to quit): ";
while (cin >> target) {
cout << "Enter step length: ";
if (!(cin >> dstep)) break;
while (result.magval() < target) {
direction = rand() % 360; //generate 0-359 random number
step.reset(dstep, direction, Vector::POL);
result = result + step;
steps++;
}
cout << "After " << steps << " steps, the subject has the following location:\n";
cout << result << endl;
result.polar_mode();
cout << " or\n" << result << endl;
cout << "Average outward distance per step = "
<< result.magval() / steps << endl;
steps = 0;
result.reset(0.0, 0.0);
cout << "Enter target distance (q to quit): ";
}
cout << "Bye!\n";
cin.clear();
while (cin.get() != '\n') continue;
return 0;
}
xiti_c11_1.cpp
#include <iostream>
#include <fstream>
#include <cstdlib> // rand srand
#include <ctime> //time
#include "vector.h"
int main() {
using namespace std;
using VECTOR::Vector;
srand(time(0)); // time(0) the current time, srand reset random seed.
double direction;
Vector step;
Vector result(0.0, 0.0);
unsigned long steps = 0;
double target;
double dstep;
ofstream outFile;
outFile.open("randwalk.txt");
cout << "Enter target distance (q to quit): ";
while (cin >> target) {
cout << "Enter step length: ";
if (!(cin >> dstep)) break;
outFile << "Target Distance: " << target << ", Step Size: " << dstep << endl;
outFile << steps << ": " << result << endl;
while (result.magval() < target) {
direction = rand() % 360; //generate 0-359 random number
step.reset(dstep, direction, Vector::POL);
result = result + step;
steps++;
outFile << steps << ": " << result << endl;
}
cout << "After " << steps << " steps, the subject has the following location:\n";
outFile << "After " << steps << " steps, the subject has the following location:\n";
cout << result << endl;
outFile << result << endl;
result.polar_mode();
cout << " or\n" << result << endl;
outFile << " or\n" << result << endl;
cout << "Average outward distance per step = "
<< result.magval() / steps << endl;
outFile << "Average outward distance per step = "
<< result.magval() / steps << endl;
steps = 0;
result.reset(0.0, 0.0);
cout << "Enter target distance (q to quit): ";
}
cout << "Bye!\n";
cin.clear();
while (cin.get() != '\n') continue;
outFile.close();
return 0;
}
这个习题重温了下ofstream文件输出流的用法,其他没啥好说的,算是对Vector类的另外一个测试使用例子。
5.Stonewt类如下所示,现在需要重新编写它,使它有一个状态成员,由该成员控制对象应转换为英石格式、整数磅格式还是浮点磅格式。重载<<运算符,使用它来替换show_stn( )和show_lbs( )方法。重载加法、减法和乘法运算符,以便可以对Stonewt值进行加、减、乘运算。编写一个使用所有类方法和友元的小程序,来测试这个类。
6.重载全部6个关系运算符。运算符对pounds成员进行比较,并返回一个bool值。编写一个程序,它声明一个包含6个Stonewt对象的数组,并在数组声明中初始化前3个对象。然后使用循环来读取用于设置剩余3个数组元素的值。接着报告最小的元素、最大的元素以及大于或等于11英石的元素的数量(最简单的方法是创建一个Stonewt对象,并将其初始化为11英石,然后将其同其他对象进行比较)。
stonewt.h
#pragma once
#ifndef STONEWT_H_
#define STONEWT_H_
class Stonewt {
private:
const int Lbs_per_stn = 14;
int stone;
double pds_left;
double pounds;
public:
Stonewt(double lbs); // input pounds
Stonewt(int stn, double lbs); // input how many stone and how many pounds lefted
Stonewt();
~Stonewt();
void show_lbs() const; // show in pound format
void show_stn() const; // show in stone format
//conversion function
operator int() const;
operator double() const;
};
#endif // !STONEWT_H_
stonewt.cpp
#include <iostream>
#include <cmath>
#include "stonewt.h"
using std::cout;
Stonewt::Stonewt(double lbs) {
stone = int(lbs) / Lbs_per_stn;
pds_left = int(lbs) % Lbs_per_stn + lbs - int(lbs);
pounds = lbs;
}
Stonewt::Stonewt(int stn, double lbs) {
stone = stn;
pds_left = lbs;
pounds = stn * Lbs_per_stn + lbs;
}
Stonewt::Stonewt() {
stone = pds_left = pounds = 0;
}
Stonewt::~Stonewt() {
}
void Stonewt::show_stn()const {
cout << stone << " stone, " << pds_left << " pounds\n";
}
void Stonewt::show_lbs()const {
cout << pounds << " pounds\n";
}
Stonewt::operator int()const {
return round(pounds);
}
Stonewt::operator double()const {
return pounds;
}
上面利用了cmath的round函数来达到四舍五入的效果,int取整的话只是截断。然后用英石表达的话该类会存储pds_left作为剩余的那一点pound,第二个构造函数 Stonewt::Stonewt(int stn, double lbs) 输入的就是多少英石然后还剩下多少磅的格式。
stonewt.h
#pragma once
#ifndef STONEWT_H_
#define STONEWT_H_
class Stonewt {
public:
enum Mode { STONE, POUND, INT_POUND};
private:
const int Lbs_per_stn = 14;
int stone;
Mode state;
double pds_left;
double pounds;
public:
Stonewt(double d, Mode mode=POUND); // mode pound
Stonewt(int s, double lbs=0, Mode mode = STONE); // mode stone or int_pound
Stonewt();
~Stonewt();
void stone_mode();
void pound_mode();
void int_pound_mode();
//conversion function
explicit operator int() const;
explicit operator double() const;
//operator overloading
Stonewt operator+(const Stonewt& b) const;
Stonewt operator-(const Stonewt& b) const;
Stonewt operator*(double n)const;
void operator=(const Stonewt& b);
// operator compare
bool operator<(const Stonewt& b) const;
bool operator>(const Stonewt& b) const;
bool operator>=(const Stonewt& b) const;
bool operator<=(const Stonewt& b) const;
bool operator==(const Stonewt& b) const;
bool operator!=(const Stonewt& b) const;
//friends
friend Stonewt operator*(double n, const Stonewt& a);
friend std::ostream& operator<<(std::ostream& os, const Stonewt& v);
};
#endif // !STONEWT_H_
stonewt.cpp
#include <iostream>
#include <cmath>
#include "stonewt.h"
using std::cout;
Stonewt::Stonewt(double d, Mode mode) {
if (mode != POUND) {
cout << "error: POUND mode only, init it with default empty constructor.";
stone = pds_left = pounds = 0;
state = POUND;
}
else {
stone = int(d) / Lbs_per_stn;
pds_left = int(d) % Lbs_per_stn + d - int(d) ;
pounds = d ;
state = mode;
}
}
Stonewt::Stonewt(int s, double lbs, Mode mode) {
if (mode == INT_POUND) {
stone = s / Lbs_per_stn;
pds_left = s % Lbs_per_stn;
pounds = s;
state = mode;
}
else if (mode == STONE) {
stone = s;
pds_left = lbs;
pounds = s * Lbs_per_stn + lbs;
state = mode;
}
else {
cout << "error: INT_POUND or STONE mode only, init it with default empty constructor.";
stone = pds_left = pounds = 0;
state = POUND;
}
}
Stonewt::Stonewt() {
stone = pds_left = pounds = 0;
state = POUND;
}
Stonewt::~Stonewt() {
}
void Stonewt::stone_mode() {
state = STONE;
}
void Stonewt::pound_mode() {
state = POUND;
}
void Stonewt::int_pound_mode() {
state = INT_POUND;
}
Stonewt::operator int()const {
if (state == STONE) {
return stone;
}
else if (state == INT_POUND|| state == POUND) {
return round(pounds);
}else {
cout << "invalid mode!";
}
}
Stonewt::operator double()const {
if (state == STONE) {
return double(stone);
}
else if (state == INT_POUND || state == POUND) {
return pounds;
}
else {
cout << "invalid mode!";
}
}
void Stonewt::operator=(const Stonewt& b) {
stone = b.stone;
pds_left = b.pds_left;
pounds = b.pounds;
state = b.state;
}
Stonewt Stonewt::operator+(const Stonewt& b)const {
return Stonewt(pounds + b.pounds);
}
Stonewt Stonewt::operator-(const Stonewt& b)const {
return Stonewt(pounds - b.pounds);
}
Stonewt Stonewt::operator*(double n)const {
return Stonewt(n * pounds);
}
Stonewt operator*(double n, const Stonewt& a) {
return a * n;
}
std::ostream& operator<<(std::ostream& os, const Stonewt& v) {
if (v.state == Stonewt::POUND) {
os << v.pounds << " pounds\n";
}
else if (v.state == Stonewt::INT_POUND) {
os << round(v.pounds) << " pounds\n";
}
else if (v.state == Stonewt::STONE) {
os << v.stone << " stone, " << v.pds_left << " pounds\n";
}
else {
os << "Stonewt object mode is invalid.";
}
return os;
}
bool Stonewt::operator<(const Stonewt& b) const {
if (state == STONE) {
return pounds < b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) < round(b.pounds);
}
else if (state == POUND) {
return pounds < b.pounds;
}
else {
cout << "invalid mode!";
}
}
bool Stonewt::operator>(const Stonewt& b) const {
if (state == STONE) {
return pounds > b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) > round(b.pounds);
}
else if (state == POUND) {
return pounds > b.pounds;
}
else {
cout << "invalid mode!";
}
}
bool Stonewt::operator<=(const Stonewt& b) const {
if (state == STONE) {
return pounds <= b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) <= round(b.pounds);
}
else if (state == POUND) {
return pounds <= b.pounds;
}
else {
cout << "invalid mode!";
}
}
bool Stonewt::operator>=(const Stonewt& b) const {
if (state == STONE) {
return pounds >= b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) >= round(b.pounds);
}
else if (state == POUND) {
return pounds >= b.pounds;
}
else {
cout << "invalid mode!";
}
}
bool Stonewt::operator==(const Stonewt& b) const {
if (state == STONE) {
return pounds == b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) == round(b.pounds);
}
else if (state == POUND) {
return pounds == b.pounds;
}
else {
cout << "invalid mode!";
}
}
bool Stonewt::operator!=(const Stonewt& b) const {
if (state == STONE) {
return pounds != b.pounds;
}
else if (state == INT_POUND) {
return round(pounds) != round(b.pounds);
}
else if (state == POUND) {
return pounds != b.pounds;
}
else {
cout << "invalid mode!";
}
}
xiti_c11_5.cpp
#include <iostream>
#include "stonewt.h"
int main() {
using namespace std;
Stonewt stonewt_array[6] = {
{9,2.8,Stonewt::STONE},
{11,0,Stonewt::STONE},
{6.3},
};
for (int x = 3; x < 6; x++) {
cout << "Please input object weight in pounds: ";
double pounds;
cin >> pounds;
stonewt_array[x] = Stonewt(pounds);
}
Stonewt *max = stonewt_array;
Stonewt *min = stonewt_array;
int count = 0;
for (int i = 0; i < 6; i++) {
cout << stonewt_array[i];
}
cout << "----------------------\n";
for (int i=0; i < 6; i++) {
if (stonewt_array[i] < *min) {
min = &stonewt_array[i];
}
if (stonewt_array[i] > *max) {
max = &stonewt_array[i];
}
if (stonewt_array[i] == Stonewt(11, 0, Stonewt::STONE)) {
count++;
}
}
cout << "equal 11 stone elements number is: " << count << endl;
cout << "max = " << *max;
cout << "min = " << *min;
cout << "max - min = " << *max - *min;
cout << "2 * max = " << 2 * *max;
return 0;
}
本例子新的知识点倒没有,但里面东西还是挺多的,基本上是对本章节大部分内容的一个整理和总结,需要读者细细阅读体会。
7.复数有两个部分组成:实数部分和虚数部分。复数的一种书写方式是:(3.0,4.0),其中,3.0是实数部分,4.0是虚数部分。假设a = (A, Bi),c = (C, Di),则下面是一些复数运算。
- 加法:
a + c = (A+C, (B+D)i)。 - 减法:
a – c = (A−C, (B−D)i)。 - 乘法:
a * c = (A*C−B*D, (A*D + B*C)i)。 - 乘法:
x*c = (x * C, x *Di),其中x为实数。
请定义一个复数类,以便下面的程序可以使用它来获得正确的结果。
xiti_c11_7.cpp
#include <iostream>
#include "complex0.h"
int main() {
//int main54() {
using namespace std;
complex a(3.0, 4.0);
complex c;
cout << "Enter a complex number (q to quit): \n";
while (cin >> c) {
cout << "c is " << c << endl;
cout << "complex conjugate is " << ~c << endl;
cout << "a is " << a << endl;
cout << "a + c is " << a + c << endl;
cout << "a - c is " << a - c << endl;
cout << "a * c is " << a * c << endl;
cout << "2 * c is " << 2 * c << endl;
cout << "Enter a complex number (q to quit): \n";
}
cout << "Done!\n";
return 0;
}
注意,必须重载运算符<<和>>。标准C++使用头文件complex提供了比这个示例更广泛的复数支持,因此应将自定义的头文件命名为complex0.h,以免发生冲突。应尽可能使用const。
下面是该程序的运行情况。

请注意,经过重载后,cin >>c将提示用户输入实数和虚数部分。
complex0.h
#pragma once
#ifndef COMPLEX0_H_
#define COMPLEX0_H_
#include <iostream>
class complex {
private:
double real; //real
double img; // img
public:
complex();
complex(double a, double b);
~complex();
//operator overloading
complex operator+(const complex& b) const;
complex operator-(const complex& b) const;
complex operator-()const;
complex operator*(double n)const;
complex operator*(complex& b)const;
complex operator~()const;
//friends
friend complex operator*(double n, const complex& a);
friend std::ostream& operator<<(std::ostream& os, const complex& v);
friend std::istream& operator>>(std::istream& os, complex& v);
};
#endif //
complex0.cpp
#include "complex0.h"
complex::complex() {
real = 0;
img = 0;
}
complex::complex(double a, double b) {
real = a;
img = b;
}
complex::~complex() {
}
complex complex::operator+(const complex& b) const {
return complex(real + b.real, img + b.img);
}
complex complex::operator-(const complex& b) const {
return complex(real - b.real, img - b.img);
}
complex complex::operator-()const {
return complex(-real, -img);
}
complex complex::operator*(complex& b)const {
return complex((real * b.real - img * b.img), (real * b.img + img * b.real));
}
complex complex::operator*(double n)const {
return complex(n * real, n * img);
}
complex complex::operator~()const {
return complex(real, -img);
}
complex operator*(double n, const complex& a) {
return a * n;
}
std::ostream& operator<<(std::ostream& os, const complex& v) {
os << "(" << v.real << "," << v.img << "i)";
return os;
}
std::istream& operator>>(std::istream& os, complex& v) {
using std::cout;
double a;
double b;
cout << "real: ";
os >> v.real;
os.get();
cout << "imaginary: ";
os >> v.img;
os.get();
return os;
}
类和动态内存分配
本小节主要分析讨论了官方内置的string类是如何实现不定长度字符串功能支持的,前面在介绍动态内存分配new和delete的时候提到过其内部就是利用的new和delete来实现了内部字符数组长度的可定制,但具体到实现层面,里面还有很多细节和问题需要讨论。
首先看一下参考资料1列出的StringBad这个带有一些bug的实现版本,该版本写法很直观,我想没有学习本小节的内容的读者一开始应该都会写出这样的最初实现版本:
stringbad.h
#include <iostream>
#ifndef STRINGBAD_H_
#define STRINGBAD_H_
class StringBad{
private:
char * str;
int len;
public:
StringBad(const char * s);
StringBad();
~StringBad();
friend std::ostream & operator<<(std::ostream & os, const StringBad & st);
};
#endif
stringbad.cpp
#include <cstring>
#include "stringbad.h"
using std::cout;
StringBad::StringBad(const char * s){
len = std::strlen(s);
str = new char[len+1];
std::strcpy(str,s);
}
StringBad::StringBad(){
len = 0;
str = new char[1];
str[0] = '\0';
}
StringBad::~StringBad(){
delete [] str;
}
std::ostream & operator<<(std::ostream & os, const StringBad & st){
os << st.str;
return os
}
StringBad类里面只保留了字符数组的指针,具体字符数组是存储在动态数组里面的。上面的实现有以下两大缺陷,一是没有正确应对复制构造函数的情况;二是没有正确应对赋值运算符的情况。
首先我们来分析第一个情况,参考资料callme2为什么会出现bug。因为callme2函数采用的是将类对象按值传递的形式,那么将调用该类的复制构造函数来完成这个动作,具体到这里可以理解为默认执行了 StringBad sb = StringBad(headline2) 。
因为上面的类实现并没有定义这个复制构造函数,那么将调用类的默认复制构造函数,具体就是非静态私有成员的值赋值,大概执行类似下面的语句:
StringBad sb;
sb.str = headline.str;
sb.len = headline.len;
除了函数的按值传递情况外,下面的语句也是明确的在调用复制构造函数:
StringBad ditto(motto);
StringBad metto = motto;
StringBad also = StringBad(motto);
StringBad * pstringBad = new StringBad(motto);
这其中 StringBad metto = motto; 可能在具体实现上会有点差异,如果写成下面这种形式:
StringBad metto;
metto = motto;
那么肯定上一句是调用默认的构造函数,第二句是调用的赋值运算符。但如果写成一句:StringBad metto = motto; 则有的可能就是只调用了复制构造函数,有的可能是先用复制构造函数创建一个临时对象,然后又再调用了赋值运算符。
继续到具体这个例子的讨论上,callme2按值传递内部形参sb,出了函数就将调用sb的析构函数,又因为sb的str指针就是headline2的str指针,所以sb的析构函数将会把该字符数组在动态内存里面的内容删除掉,从而造成了后面显示headline2的bug。
定义一个显式的复制构造函数可以解决这个问题【这种深究类里面成员的指针拷贝问题的叫做深度复制】:
StringBad::StringBad(const StringBad & st){
len = st.len;
str = new char[len+1];
std::strcpy(str, st.str);
}
上面例子的第二个bug是没有正确应对赋值运算符的情况,也就是这种情况:
StringBad metto;
metto = motto;
同样类也有默认的 operator= 成员函数,其行为和复制构造函数类似,也是对类的非静态成员逐个复制。要解决这个问题,重载赋值运算符= 即可:
StringBad & StringBad::operator=(const StringBad & st){
if (this == &st){
return *this;
}
delete [] str;
len = str.len;
str = new char[len+1];
std::strcpy(str, st.str);
return *this;
}
上面的代码可能读者会对 this == &st 有点困惑,这里一定要记住引用变量从定义的时候就绑定了某个变量,后面提到它实际上就是提到那个变量,后面不要去谈论引用变量的地址或者引用变量存储的值之类的概念,比如上面的st,你问st的值是多少,它的值就是引用的StringBad那个对象,&st ,st的取址是多少,st的地址就是StringBad那个对象的取地址操作。
还有其他一下便捷的方法和运算符重载好让该类更好用,但在这里不是讨论的重点了,除了上面的赋值运算符还需要支持 metto = "abc" 这种形式,具体就是重载赋值运算符:
StringBad & StringBad::operator=(const char * s){
delete [] str;
len = std::strlen(s);
str = new char[len+1];
std::strcpy(str, s);
return *this;
}
下面是参考资料1的一个例子,队列模拟,请读者详细阅读理解之,后面我会跟上一些觉得需要说明的知识点。关于队列的知识点这里预先假设读者已经知道了。
queue.h
#pragma once
#ifndef QUEUE_H_
#define QUEUE_H_
class Customer {
private:
long arrive;
int processtime;
public:
Customer() { arrive = processtime = 0; };
void set(long when);
long when()const { return arrive; }
int ptime()const { return processtime; }
};
typedef Customer Item;
class Queue {
private:
struct Node {
Item item;
struct Node* next;
};
enum {Q_SIZE=10};
Node* front;
Node* rear;
int items;
const int qsize;
Queue(const Queue & q):qsize(0){}
Queue& operator=(const Queue& q) { return *this; }
public:
Queue(int qs = Q_SIZE);
~Queue();
bool isempty()const;
bool isfull()const;
int queuecount()const;
bool enqueue(const Item& item);
bool dequeue(Item& item);
};
#endif // !QUEUE_H_
成员初始化列表
这里有一行代码会比较费解:
Queue(const Queue & q):qsize(0){}
这个写法只能用于类的构造函数,即在类的构造函数后面可以跟上冒号,然后后面跟上一些该类成员初始化时候的默认值。具体叫做成员初始化列表。
上面语句的写法就是该类初始化之后还会执行 qsize = 0 这个动作,为什么不直接写上这个语句呢,因为qsize这个变量如果加上 const 关键词那么是不能再设置了【看类的定义哪里 const int qsize】,那么这个时候就必须采用这种成员初始化列表的写法:
然后成员初始化列表只在构造函数具体定义时写上,声明的时候可以不写。
queue.cpp
#include <cstdlib>
#include "queue.h"
Queue::Queue(int qs) :qsize(qs) {
front = rear = NULL;
items = 0;
}
Queue::~Queue() {
Node* temp;
while (front !=NULL){
temp = front;
front = front->next;
delete temp
}
bool Queue::isempty()const {
return items == 0;
}
bool Queue::isfull()const {
return items == qsize;
}
int Queue::queuecount()const {
return items;
}
bool Queue::enqueue(const Item& item) {
if (isfull) {
return false;
}
Node* add = new Node;
add->item = item;
add->next = NULL;
items++;
if (front == NULL) {
front = add;
}
else {
rear->next = add;
}
rear = add;
return true;
}
bool Queue::dequeue(Item& item) {
if (front == NULL) {
return false;
}
item = front->item;
items--;
Node* temp = front;
front = front->next;
delete temp;
if (items == 0) {
rear = NULL;
}
return true;
}
void Customer::set(long when) {
processtime = std::rand() % 3 + 1;
arrive = when;
}
NULL空指针
你可以声明一个指针,然后让这个指针为空。通常是用NULL或者0赋值给这个指针变量:
int * ptr;
ptr = NULL;
当然推荐使用C++11新引入的关键字 nullptr :
int * ptr;
ptr = nullptr;
在本例子中该Queue类里面的每个Node节点都是new出来的,除了dequeue动作将最前面的Node挤出,需要delete该节点外,整个类的析构函数也需要对Queue类里面的所有节点进行全部delete动作。
上面实现中enqueue和dequeue这两个成员函数需要细细看下,其中dequeue接受的参数是为了记录好挤出的那个Node的数据值。除此之外dequeue动作和析构函数的动作还是很接近的。enqueue里面这一句 rear->next = add; 是为了队列倒数第二个元素能够指向倒数第一个元素。
bank.cpp
#include <iostream>
#include <cstdlib>
#include <ctime>
#include "queue.h"
const int MIN_PER_HR = 60;
bool newcustomer(double x);
bool newcustomer(double x) {
return (std::rand() * x / RAND_MAX < 1);
}
int main() {
using std::cin;
using std::cout;
using std::endl;
using std::ios_base;
std::srand(std::time(0));
cout << "Case Study: Bank of Heather Automatic Teller\n";
cout << "Enter maximum size of queue: ";
int qs;
cin >> qs;
Queue line(qs);
cout << "Enter the number of simulation hours: ";
int hours;
cin >> hours;
long cyclelimit = MIN_PER_HR * hours;
cout << "Enter the average number of customers per hour: ";
double perhour;
cin >> perhour;
double min_per_cust;
min_per_cust = MIN_PER_HR / perhour;
Item temp;
long turnaways = 0;
long customers = 0;
long served = 0;
long sum_line = 0;
int wait_time = 0;
long line_wait = 0;
for (int cycle = 0; cycle < cyclelimit; cycle++) {
if (newcustomer(min_per_cust)) {
if (line.isfull()) {
turnaways++;
}else {
customers++;
temp.set(cycle);
line.enqueue(temp);
}
}
if (wait_time <= 0 && !line.isempty()) {
line.dequeue(temp);
wait_time = temp.ptime();
line_wait += cycle - temp.when();
served++;
}
if (wait_time > 0) {
wait_time--;
}
sum_line += line.queuecount();
}
if (customers > 0) {
cout << "customers accepted: " << customers << endl;
cout << "customers served: " << served << endl;
cout << " turnaways: " << turnaways << endl;
cout << "average queue size: ";
cout.precision(2);
cout.setf(ios_base::fixed, ios_base::floatfield);
cout << (double)sum_line / cyclelimit << endl;
cout << "average wait time: "
<< (double)line_wait / served << "minutes\n";
}
else {
cout << "No customers!\n";
}
cout << "Done!\n";
return 0;
}
这个例子最重要的是跟上作者如何试着用编程来模拟现实世界问题的思路,具体编程上的细节问题前面都已经说过了。下面我会多说一点。
这里的cycle下面的循环语句相当于这个世界的心跳,每分钟会执行下面的动作。第一个是来看是否有新顾客,如果有新顾客会如何;第二个if和第三个if是看最前面的那个顾客业务处理完了没,通过wait_time 来衡量,其小于0就认为该顾客业务处理完了。
首先来看新顾客的模拟,(std::rand() * x / RAND_MAX < 1) 代码的这里会比较难懂一点,我们知道 rand会生成从0到最大整数的随机整数,所以 std::rand() * x / RAND_MAX 会生成0到x之间的随机整数,而x的含义是每个顾客平均几分钟。我们假设一条时间线,那么在这条时间线上平均x分钟画一条刻度,该刻度意思就是来了一个新顾客。因为随机数0到x概率分布均匀,所以可以认为上面运算公式得到bool为真的概率为1/x 。或者说该概率公式运行x个必然会得到一个刻度,而这和最开始定义的该时间线每x分钟画一个刻度表示来一个新用户是一致的,简单来说这个随机数函数返回true意思是一个新顾客来了。
新顾客来了会记录自身到达的时间,然后分配给一个1-3的业务处理时间属性。然后我们继续往下看,队列开始挤出最开头的那个顾客,意思是那个顾客开始处理自己的业务了,获取该顾客的业务处理时间,后面是一些统计信息处理。下一分钟会判断该顾客业务处理完了没有,没完则等待时间减去一,完了也就是等待时间wait_time<=0了那么继续处理下一个顾客。【这个模拟顾客业务处理时间和心跳时间还可以细一点,不过这不是重点。】在后面是一些统计数据的计算,都很简单。
1.对于下面的类声明:
class Cow{
char name[20];
char * hobby;
double weight;
public:
Cow();
Cow(const char * nm, const char * ho, double wt);
Cow(const Cow & c);
~Cow();
Cow & operator=(const Cow & c);
void ShowCow() const;
};
给这个类提供实现,并编写一个使用所有成员函数的小程序。
xiti_c12_1.cpp
#include <iostream>
#include <cstring>
using std::cout;
using std::endl;
class Cow {
char name[20];
char* hobby;
double weight;
public:
Cow();
Cow(const char* nm, const char* ho, double wt);
Cow(const Cow& c);
~Cow();
Cow& operator=(const Cow& c);
void ShowCow() const;
};
Cow::Cow() {
name[0] = '\0';
hobby = new char[1];
hobby[0] = '\0';
weight = 0;
}
Cow::Cow(const char* nm, const char* ho, double wt) {
strcpy_s(name, nm);
int len = strlen(ho);
hobby = new char[len+1];
strcpy_s(hobby, len+1,ho);
weight = wt;
}
Cow::Cow(const Cow& c) {
strcpy_s(name, c.name);
int len = strlen(c.hobby);
hobby = new char[len + 1];
strcpy_s(hobby, len+1,c.hobby);
weight = c.weight;
}
Cow::~Cow() {
delete[] hobby;
}
Cow& Cow::operator=(const Cow& c) {
if (this == &c) return *this;
strcpy_s(name, c.name);
int len = strlen(c.hobby);
delete[] hobby;
hobby = new char[len + 1];
strcpy_s(hobby, len+1,c.hobby);
weight = c.weight;
return *this;
}
void Cow::ShowCow()const {
cout << "Cow " << name << " hobby is" << hobby << " and it's weight is " << weight << endl;
}
int main() {
Cow cow1;
Cow cow2 = Cow("sucy", "reading", 18.9);
cow1.ShowCow();
cow2.ShowCow();
cow1 = cow2;
cow1.ShowCow();
cow2.ShowCow();
Cow cow3 = cow2;
cow1.ShowCow();
cow2.ShowCow();
cow3.ShowCow();
return 0;
}
本例也在告诉我们这样一个事实,那就是类里面如果有某个成员是指针变量,那么通常是要通过动态内存分配来重新实现复制构造函数和赋值运算符和析构函数的。 赋值运算和复制构造函数的区别在于赋值运算该类对象已经初始化了,也就是已经分配动态内存了,再次赋值需要将原来分配的内存里面的值释放掉。
4.请参看下面的Stack类的头文件:
typedef unsigned long Item;
class Stack {
private:
enum { MAX = 10 };
Item * pitems;
int size;
int top;
public:
Stack(int n = MAX);
Stack(const Stack& st);
~Stack();
bool isempty()const;
bool isfull() const;
bool push(const Item& item);
bool pop(Item& item);
Stack& operator=(const Stack& st);
};
正如私有成员表明的,这个类使用动态分配的数组来保存栈项。请重新编写方法,以适应这种新的表示法,并编写一个程序来演示所有的方法,包括复制构造函数和赋值运算符。
xiti_c12_4.cpp
#include <iostream>
#include <cctype>
typedef unsigned long Item;
class Stack2 {
private:
enum { MAX = 10 };
Item * pitems;
int size;
int top;
public:
Stack2(int n = MAX);
Stack2(const Stack2& st);
~Stack2();
bool isempty()const;
bool isfull() const;
bool push(const Item& item);
bool pop(Item& item);
Stack2& operator=(const Stack2& st);
friend std::ostream& operator<<(std::ostream& os, const Stack2& s);
};
Stack2::Stack2(int n) {
size = n;
top = 0;
pitems = new Item[size];
}
std::ostream& operator<<(std::ostream& os, const Stack2& s) {
using std::endl;
os << "Stack2 size: " << s.size << endl
<< "Stack2 top: " << s.top << endl;
for (int i = 0; i < s.top; i++) {
os << "Stack values " << i << ": " << s.pitems[i] << endl;
}
return os;
}
Stack2::Stack2(const Stack2& st) {
size = st.size;
top = st.top;
pitems = new Item[size];
for (int i = 0; i < st.top; i++) {
pitems[i] = st.pitems[i];
}
}
Stack2& Stack2::operator=(const Stack2& st) {
if (this == &st) return *this;
size = st.size;
top = st.top;
delete[] pitems;
pitems = new Item[size];
for (int i = 0; i < st.top; i++) {
pitems[i] = st.pitems[i];
}
return *this;
}
Stack2::~Stack2() {
delete[] pitems;
}
bool Stack2::isempty() const {
return top == 0;
}
bool Stack2::isfull() const {
return top == size;
}
bool Stack2::push(const Item& item) {
if (top < size) {
pitems[top++] = item;
return true;
}
else {
return false;
}
}
bool Stack2::pop(Item& item) {
if (top > 0) {
item = pitems[--top];
return true;
}
else {
return false;
}
}
int main() {
using namespace std;
Stack2 st1(3);
Stack2 st2;
Item tmp;
st1.push(1);
cout << "st1-----------\n";
cout << st1;
st2 = st1;
cout << "st2------------\n";
cout << st2;
st2.pop(tmp);
st2.push(3);
st2.push(4);
cout << "st2-------------\n";
cout << st2;
Stack2 st3 = st2;
cout << "st3-------------\n";
cout << st3;
return 0;
}
本例子是在之前Stack类的基础上继续讨论的,唯一的改动就是之前的items是一个固定长度的数组,现在变成动态内存分配的了。
这里top是堆栈的顶端索引,当top等于0表示该堆栈没有元素,当top=1表示该堆栈有1个元素,但你要取值是取index=0的值。然后top++的含义是返回top之后再执行自增操作;而++top的含义是先自增再返回top的值。
5.Heather银行进行的研究表明,ATM客户不希望排队时间不超过1分钟。使用本小节上面提到的对于队列的模拟,找出要使平均等候时间为1分钟,每小时到达的客户数应为多少(试验时间不短于100小时)?
xiti_c12_5.cpp
#include <iostream>
#include <cstdlib>
#include <ctime>
#include "queue.h"
const int MIN_PER_HR = 60;
extern bool newcustomer(double x);
int main() {
using std::cin;
using std::cout;
using std::endl;
using std::ios_base;
std::srand(std::time(0));
cout << "Case Study: Bank of Heather Automatic Teller\n";
cout << "Enter maximum size of queue: ";
int qs;
cin >> qs;
Queue line(qs);
cout << "Enter the number of simulation hours: ";
int hours;
cin >> hours;
long cyclelimit = MIN_PER_HR * hours;
//cout << "Enter the average number of customers per hour: ";
//double perhour;
//cin >> perhour;
for (double perhour = 1; perhour < 100; perhour=perhour+0.1) {
double min_per_cust;
min_per_cust = MIN_PER_HR / perhour;
Item temp;
long turnaways = 0;
long customers = 0;
long served = 0;
long sum_line = 0;
int wait_time = 0;
long line_wait = 0;
for (int cycle = 0; cycle < cyclelimit; cycle++) {
if (newcustomer(min_per_cust)) {
if (line.isfull()) {
turnaways++;
}
else {
customers++;
temp.set(cycle);
line.enqueue(temp);
}
}
if (wait_time <= 0 && !line.isempty()) {
line.dequeue(temp);
wait_time = temp.ptime();
line_wait += cycle - temp.when();
served++;
}
if (wait_time > 0) {
wait_time--;
}
sum_line += line.queuecount();
}
if (customers > 0) {
cout << "customers accepted: " << customers << endl;
cout << "customers served: " << served << endl;
cout << " turnaways: " << turnaways << endl;
cout << "average queue size: ";
cout.precision(2);
cout.setf(ios_base::fixed, ios_base::floatfield);
cout << (double)sum_line / cyclelimit << endl;
cout << "average wait time: "
<< (double)line_wait / served << "minutes\n";
}
else {
cout << "No customers!\n";
}
if ((double)line_wait / served > 1) {
cout << "average wait time is larger than 1 minutes\n";
cout << "the largest perhour parameter is: " << perhour << endl;
break;
}
}
cout << "Done!\n";
return 0;
}
本习题在之前讨论的基础上稍作修改,主要还是对前面讨论的ATM排队问题理解透彻即可。
类继承
C++类的继承就面向对象编程那些概念上和其他编程语言都是一样的,不过具体实现细节上区别还是很大的。这其中最大的一个区别是在C++中派生类不可以使用基类的私有变量,而只能使用基类的公有方法,而且派生类的构造函数也必须使用基类的构造函数。也就是创建一个派生类对象,必须首先创建一个基类对象,如下所示:
RatedPlayer::RatedPlayer(unsigned int r, const string& fn, const string& ln, bool ht) : TableTennisPlayer(fn, ln,ht){
rating = r;
}
按照成员初始化列表的定义,可见派生类是有其基类的定义的,而且其构造函数实现必须基于基类的构造函数。因为这是C++语言实现上的定义,所以你在定义派生类构造函数的时候没有使用上面的成员初始化列表来初始化基类构造函数,那么也将调用默认的基类构造函数。
下面这个演示例子为了方便头文件就不分开了:
test_inherit.cpp
#include <string>
#include <iostream>
using std::string;
class TableTennisPlayer {
private:
string firstname;
string lastname;
bool hasTable;
public:
TableTennisPlayer(const string& fn = "none", const string& ln = "none", bool ht = false);
void Name() const;
bool HasTable() const { return hasTable; };
void ResetTable(bool v) { hasTable = v; };
};
TableTennisPlayer::TableTennisPlayer(const string& fn, const string & ln, bool ht): firstname(fn),lastname(ln),hasTable(ht){}
void TableTennisPlayer::Name() const {
std::cout << lastname << ", " << firstname;
}
class RatedPlayer : public TableTennisPlayer {
private:
unsigned int rating;
public:
RatedPlayer(unsigned int r = 0, const string& fn = "none", const string& ln = "none", bool ht = false);
RatedPlayer(unsigned int r, const TableTennisPlayer& tp);
unsigned int Rating()const { return rating; };
void ResetRating(unsigned int r) { rating = r; };
};
RatedPlayer::RatedPlayer(unsigned int r, const string& fn, const string& ln, bool ht) : TableTennisPlayer(fn, ln,ht){
rating = r;
}
RatedPlayer::RatedPlayer(unsigned int r, const TableTennisPlayer& tp) : TableTennisPlayer(tp) {
rating = r;
}
int main(void) {
using std::cout;
using std::endl;
TableTennisPlayer player1("Tara", "Boomdea", false);
RatedPlayer rplayer1(1140, "Mallory", "Duck", true);
rplayer1.Name();
if (rplayer1.HasTable()) {
cout << ": has a table.\n";
}
else {
cout << ": hasn't a table.\n";
}
player1.Name();
if (player1.HasTable()) {
cout << ": has a table.\n";
}
else {
cout << ": hasn't a table.\n";
}
cout << "Name: ";
rplayer1.Name();
cout << "; Rating: " << rplayer1.Rating() << endl;
RatedPlayer rplayer2(1212, player1);
cout << "Name: ";
rplayer2.Name();
cout << "; Rating: " << rplayer2.Rating() << endl;
return 0;
}
上面例子中的这几行代码值得说一下:
RatedPlayer::RatedPlayer(unsigned int r, const TableTennisPlayer& tp) : TableTennisPlayer(tp) {
rating = r;
}
TableTennisPlayer接受了一个同类对象,其将自动调用TableTennisPlayer的复制构造函数,上面是没有定义的,这里之所以行得通是因为默认的复制构造函数是可行的。
继承类的析构函数执行顺序是先执行本类的析构函数,再调用基类的析构函数。
在继承关系中,继承类可以使用基类指针或引用,不过基类不可以使用派生类指针或引用:
RatedPlayer rplayer1(1140, "Mallory", "Duck", true);
TableTennisPlayer & rt = rplayer1;
TableTennisPlayer * pt = &rplayer1;
rt.Name();
pt->Name();
如果采用上面这种继承类使用基类指针或引用的风格,则只能调用基类的方法。
虚方法
在继承关系中,基类和派生类的某个方法有重载行为,如果你看到基类,一般也包括派生类的某个方法声明如下:
virtual void Name() const;
那么这个方法叫做虚方法。在前面提到了继承类使用基类指针或引用这种写法,在这种写法下,如果对应的方法不是虚方法,那么当调用 rt.Name() 的时候,调用的是 TableTennisPlayer::Name() ,如果对应的方法声明为虚方法了,那么程序会根据指针或引用对应的类型来选择方法,比如前面例子假设 Name() 已经声明为虚方法了,那么调用 rt.Name() 使用的是 RatedPlayer::Name() 。
所以虚方法是很方便的,一般这种情况基类和派生类对应的方法都声明为虚方法。
虚方法具体定义实现不需要再加上virtual关键字了。
下面请读者阅读学习 test_brass.cpp 这个例子:
#include <string>
#include <iostream>
using std::string;
using std::cout;
using std::endl;
// formatting stuff
typedef std::ios_base::fmtflags format;
typedef std::streamsize precis;
format setFormat();
void restore(format f, precis p);
class Brass {
private:
string fullName;
long acctNum;
double balance;
public:
Brass(const string& s = "Nullbody", long an = -1, double bal = 0.0);
void Deposit(double amt);
virtual void Withdraw(double amt);
double Balance() const;
virtual void ViewAcct() const;
virtual ~Brass() {};
};
Brass::Brass(const string& s, long an, double bal) {
fullName = s;
acctNum = an;
balance = bal;
}
void Brass::Deposit(double amt) {
if (amt < 0) {
cout << "Negative deposit not allowed; "
<< "deposit is cancelled.\n";
}
else {
balance += amt;
}
}
void Brass::Withdraw(double amt) {
format initialState = setFormat();
precis prec = cout.precision(2);
if (amt < 0) {
cout << "Withdraw amout must be positive;"
<< "withdraw canceled.\n";
}else if (amt <= balance) {
balance -= amt;
}
else {
cout << "Withdraw amout of $" << amt << "exceeds your balance.\n"
<< "withdraw canceled.\n";
}
restore(initialState, prec);
}
double Brass::Balance()const {
return balance;
}
void Brass::ViewAcct()const {
format initialState = setFormat();
precis prec = cout.precision(2);
cout << "Client: " << fullName << endl;
cout << "Account Number: " << acctNum << endl;
cout << "Balance: $" << balance << endl;
restore(initialState, prec);
}
class BrassPlus : public Brass {
private:
double maxLoan;
double rate;
double owesBank;
public:
BrassPlus(const string& s = "Nullbody", long an = -1, double bal = 0.0, double ml = 500, double r= 0.11125);
BrassPlus(const Brass & ba, double ml = 500, double r=0.11125);
virtual void ViewAcct()const;
virtual void Withdraw(double amt);
void ResetMax(double m) { maxLoan = m; };
void ResetRate(double r) { rate = r; };
void ResetOwes() { owesBank = 0; };
};
BrassPlus::BrassPlus(const string& s , long an , double bal, double ml, double r) : Brass(s, an, bal) {
maxLoan = ml;
owesBank = 0.0;
rate = r;
}
BrassPlus::BrassPlus(const Brass& ba, double ml, double r) : Brass(ba) {
maxLoan = ml;
owesBank = 0.0;
rate = r;
}
void BrassPlus::ViewAcct()const {
format initialState = setFormat();
precis prec = cout.precision(2);
Brass::ViewAcct();
cout << "Maximum load: $" << maxLoan << endl;
cout << "Owed to bank: $" << owesBank << endl;
cout.precision(3);
cout << "Load Rate: " << 100 * rate << "%\n";
restore(initialState, prec);
}
void BrassPlus::Withdraw(double amt) {
format initialState = setFormat();
precis prec = cout.precision(2);
double bal = Balance();
if (amt <= bal) {
Brass::Withdraw(amt);
}
else if (amt <= bal + maxLoan -owesBank) {
double advance = amt - bal;
owesBank += advance * (1.0 + rate);
cout << "Band advance: $" << advance << endl;
cout << "Finance charge: $" << advance * rate << endl;
Deposit(advance);
Brass::Withdraw(amt);
}
else {
cout << "Credit limit exceeded. Transcation cancelled.\n";
}
restore(initialState, prec);
}
format setFormat() {
return cout.setf(std::ios_base::fixed, std::ios_base::floatfield);
}
void restore(format f, precis p) {
cout.setf(f, std::ios_base::floatfield);
cout.precision(p);
}
int main(void) {
Brass Piggy("Porcelot Pigg", 381299, 4000.0);
BrassPlus Hoggy("Horatio Hogg", 382288, 3000.0);
Piggy.ViewAcct();
cout << endl;
Hoggy.ViewAcct();
cout << endl;
cout << "Depositing $1000 into the Hogg Accout:\n";
Hoggy.Deposit(1000.0);
cout << "New balance: " << Hoggy.Balance() << endl;
cout << "Withdrawing $4200 from the Pigg Account" << endl;
Piggy.Withdraw(4200.0);
cout << "Pigg account balance: $" << Piggy.Balance() << endl;
cout << "Withdrawing $4200 from the Hoggy Accout:\n";
Hoggy.Withdraw(4200.0);
Hoggy.ViewAcct();
return 0;
}
protected
protected类似于public和private也是用于控制类成员的访问权限的。protected更类似于private,只有在继承关系中才有区别,区别就是派生类可以访问protected里面的成员,当然不能访问私有成员,这个前面提到过了,而对于外部世界,也就是不是在继承关系中的那些类来说,保护成员跟私有成员一样不可访问。
习题13.1
以下面的类声明为基础:
class Cd {
private:
char performers[50];
char label[20];
int selections; // number of selections
double playtime; // playing time in minutes
public:
Cd(char* s1, char* s2, int n, double x);
Cd(const Cd& d);
Cd();
~Cd();
void Report() const;
Cd& operator=(const Cd& d);
};
派生出一个Classic类,并添加一组char成员,用于存储指出CD中主要作品的字符串。修改上述声明,使基类的所有函数都是虚的。如果上述定义声明的某个方法并不需要,则请删除它。使用下面的程序测试您的产品:
#include <iostream>
#include "classic.h"
using namespace std;
void Bravo(const Cd& disk);
void Bravo(const Cd& disk) {
disk.Report();
}
int main() {
Cd c1("Beatles","Capitol", 14, 35.5);
Classic c2 = Classic("Piano Sonata in B flat, Fantasia in C", "Alfred Brendel", "Philips", 2, 57.17);
Cd * pcd = &c1;
cout << "Using object directly:\n";
c1.Report(); // use Cd method
cout << endl;
c2.Report(); // use Classic method
cout << endl;
cout << "Using type cd * pointer to objects: \n";
pcd->Report(); // use Cd method
cout << endl;
pcd = &c2;
pcd->Report(); // use Classic method
cout << endl;
cout << "Calling a function with a Cd reference argument:\n";
Bravo(c1);
cout << endl;
Bravo(c2);
cout << endl;
cout << "Testing assignment: \n";
Classic copy;
copy = c2;
copy.Report();
return 0;
}
classic.h内容如下:
#pragma once
#ifndef CLASSIC_H_
#define CLASSIC_H_
class Cd {
private:
char performers[50];
char label[20];
int selections; // number of selections
double playtime; // playing time in minutes
public:
Cd(const char* s1, const char* s2, int n, double x);
Cd(const Cd& d);
Cd();
virtual void Report() const;
Cd& operator=(const Cd& d);
virtual ~Cd() {};
};
class Classic : public Cd {
private:
char works[1000];
public:
Classic(const char* wks,const char* s1, const char* s2, int n, double x );
Classic(const char* wks,const Cd& c );
Classic();
virtual void Report() const;
Classic& operator=(const Classic& d);
};
#endif
classic.cpp文件内容如下:
#include "classic.h"
#include <cstring>
#include <iostream>
using std::cout;
using std::endl;
Cd::Cd(const char* s1, const char* s2, int n, double x) {
strcpy_s(performers, s1);
strcpy_s(label, s2);
selections = n;
playtime = x;
}
Cd::Cd(const Cd& d) {
strcpy_s(performers, d.performers);
strcpy_s(label, d.label);
selections = d.selections;
playtime = d.playtime;
}
Cd::Cd() {
performers[0] = '\0';
label[0] = '\0';
selections = 0;
playtime = 0;
}
Cd& Cd::operator=(const Cd& d) {
strcpy_s(performers, d.performers);
strcpy_s(label, d.label);
selections = d.selections;
playtime = d.playtime;
return *this;
}
void Cd::Report() const {
cout << "performers: " << this->performers << endl;
cout << "label: " << this->label << endl;
cout << "selections: " << this->selections << endl;
cout << "playtime: " << this->playtime << endl;
}
Classic::Classic(const char* wks, const char* s1, const char* s2, int n, double x) : Cd(s1, s2, n, x) {
strcpy_s(works, wks);
}
Classic::Classic(const char* wks, const Cd& c) : Cd(c) {
strcpy_s(works, wks);
}
Classic::Classic() : Cd() {
works[0] = '\0';
}
Classic& Classic::operator=(const Classic& d) {
Cd::operator=(d);
strcpy_s(works, d.works);
return *this;
}
void Classic::Report() const {
Cd::Report();
cout << "works: " << this->works << endl;
}
上面对于赋值只考虑了相同类的赋值。
拾遗
类在namespace里面更简明的声明
如下,只是简单告诉编译器该类在某个namespace里面,后面再详细写上声明。
namespace ns {
class A; // just tell the compiler to expect a class def
}
class ns::A {
// define here
};
在Qt样例项目中有这样的代码:
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QMainWindow>
QT_BEGIN_NAMESPACE
namespace Ui { class MainWindow; }
QT_END_NAMESPACE
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
MainWindow(QWidget *parent = nullptr);
~MainWindow();
private:
Ui::MainWindow *ui;
};
#endif // MAINWINDOW_H
初看上去两个MainWindow很让人迷惑,其实这两个说的是两个东西。在Ui命名空间里面的MainWindow类的具体声明是在mainwindow.ui自动生成的ui_mainwindow.h文件那里:
namespace Ui {
class MainWindow: public Ui_MainWindow {};
} // namespace Ui
如果将样例项目改成这样会更清晰一点:
#ifndef MAINWINDOW_H
#define MAINWINDOW_H
#include <QMainWindow>
QT_BEGIN_NAMESPACE
namespace Ui { class MainWindow; }
QT_END_NAMESPACE
class MyMainWindow : public QMainWindow
{
Q_OBJECT
public:
MyMainWindow(QWidget *parent = nullptr);
~MyMainWindow();
private:
Ui::MainWindow *ui;
};
#endif // MAINWINDOW_H
lambda函数写法
[](float a, float b) {
return (std::abs(a) < std::abs(b));
}
- 方括号里叫做capture clause
- 圆括号里面是lambda函数的参数
- 花括号里面是lambda函数的主体部分
类的成员函数作为函数的参数
具体看下面这个例子,是从tutorialspoint网站拷贝过来的,已经执行通过了。
#include <iostream>
using namespace std;
class AB {
public:
int sub(int a, int b) {
return a - b;
}
int div(int a, int b) {
return a / b;
}
};
//using function pointer
int res1(int m, int n, AB* obj, int(AB::* fp)(int, int)) {
return (obj->*fp)(m, n);
}
//using function pointer
int res2(int m, int n, AB* obj, int(AB::* fp2)(int, int)) {
return (obj->*fp2)(m, n);
}
int main() {
AB ob;
cout << "Subtraction is = " << res1(8, 5, &ob, &AB::sub) << endl;
cout << "Division is = " << res2(4, 2, &ob, &AB::div) << endl;
return 0;
}
我们看到成员函数的类型声明是需要将类的名字引用符加上的,然后实际调用 *fp 并不能直接调用,而需要通过对象obj来调用,因为fp 是函数指针,*fp 一般理解就是该函数地址或者该函数名。
最后就是传递值,也不能简单将该函数名写上即可,需要这样 &AB::sub 取出该成员函数的内存地址或者说指针。
enum class
C++的enum枚举类型和C语言的enum在使用上稍微有点差别,声明更简单了,其他都一样的。
enum Color {red, green, blue};
Color color; // here
color = red;
这个常规的枚举类型最大的问题就是变量名污染全局变量空间的问题,比如下面的写法:
enum {MAX=10};
后面你想要使用MAX其就是值10,但如果有多个枚举类型声明具有相同的名字的话就会出现冲突问题。为此C++提出了enum class 类作用域内的枚举类型变量。
enum class Color { red, green, blue };
Color color = Color::blue;
附录
cin详解
cin >>遇到Enter Space Tab 即结束,适合char,无空格的string和单个值的int float之类的输入。需要注意的是经过个人实践换行符还是在缓冲区的,为了把这个缓冲区消掉获得更好的输入体验,一般采用这种表达方式:(cin >> what).get(),这是因为cin >> what会返回cin对象,然后继续调用下面的 get 方法来消掉最后的换行符。cin.get和cin.getline都可以用于字符数组的行输入,不同的是 get方法不会丢弃缓冲区的换行结束符,此外cin.get还有一个重载变体,cin.get(char &ch),用于读取第一个字符,假设缓冲区下一个字符是换行符,然后在遇到cin.get()则将把那个换行符读取下来。- getline函数 ,和cin.getline的区别就是
getline(cin, string)getline会读入到C++的string类,而不是C风格的字符数组。
cout详解
cout <<一般使用cout.put(char &ch)输出一个字符,如果输入的整型也会正常显示该字符。
sizeof函数
sizeof(int)
返回目标对象的bytes大小,具体返回的是 size_t 类型,实际上就是 unsigned int 类型:
typedef unsigned int size_t;
ctypes.h库
ctypes.h 库提供了一些关于单个字符测试的函数:
- isalnum 是否是字母或者数字
- isalpha 是否是字母
- isblank 是否是空白字符【空格 水平制表符 换行符或其他本地化的空白字符】
- isdigit 是否是数字
- islower 是否是小写
- isupper 是否是大写
- isspace 是否是空白字符【空格 换行符 换页符 回车符 垂直制表符 水平制表符或其他本地化的空白字符】
- isprint 是否是可打印字符
- ispunct 是否是标点符号
此外还有转换字符函数:
- tolower 转成小写字母
- toupper 转成大写字母
printf函数
转换说明
- %d 整型
- %ld long长整型
- %o 八进制整数
- %x 十六进制整数
- %f 浮点型 十进制
- %e 浮点型 e记数法
- %c 单字符
- %s 字符串
- %p 指针
- %% 打印一个百分号
printf函数具体格式字符串类似于python的format,里面内容挺丰富的,这个可以后面再慢慢了解。下面列出几个简单的实用例子:
- "%3.1f" 打印一个浮点数,字符串宽度3,小数点后有效位数1位。
- "%10d" 打印一个整数,字符串宽度10,不足的部分左侧为空白。
- "%010d" 打印一个整数,字符串宽度10,不足的部分左侧填充为0。
scanf函数
在visual studio里面使用scanf会抛出错误:
C4996 'scanf': This function or variable may be unsafe. Consider using scanf_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
需要在 myhead.h 里面加上一行 :
#define _CRT_SECURE_NO_WARNINGS
scanf函数的使用就两条:
- 读取基本变量类型的值,变量名前面要加上
& - 读取字符串到字符数组,不要使用
&,直接使用数组名即可。
char name[40];
scanf("%s", name);
scanf函数可以接受多个输入,以空白为分隔,直到读取到指定的数目为止。不过 %c 会把空白也作为字符读取进来。
转换说明
- %c 字符型
- %d 整型
- %e %f 都会转成浮点型
- %p 指针
- %s 字符串
scanf函数也类似printf支持格式修饰符,不过scanf函数用的并不是特别多,实践中推荐使用 getchar 和 fgets 这两个函数。
返回值
scanf函数的返回值:
- 如果成功读取,则返回读取的项数【比如请求输入一个%d,则返回1】
- 如果没有读取到任何项或者用户输入不合乎规范则返回0,
- 如果scranf检测到EOF文件结尾,则返回EOF【-1】
getchar函数和putchar函数
这两个函数来自 stdio.h 库,一个是接受一个字符;一个是打印一个字符,相当于scanf和printf针对字符的精简mini版本。
ch = getchar();
putchar(ch);
参考资料
- C Primer Plus 第六版中文版
- Practical C programming Steve Oualline
- 菜鸟教程
- 计算机科学的基础 Alfred V. Aho Jeffrey D. Ullman
- C++ Primer Plus 第六版中文版
Comments !